Prediction and feature selection with supervised machine learning methods
Junyan Lu
2022-10-20
Last updated: 2022-11-10
Checks: 4 2
Knit directory: irAE_LungCancer/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20221110) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
- unnamed-chunk-12
- unnamed-chunk-14
- unnamed-chunk-15
- unnamed-chunk-18
- unnamed-chunk-20
- unnamed-chunk-21
- unnamed-chunk-24
- unnamed-chunk-26
- unnamed-chunk-27
- unnamed-chunk-30
- unnamed-chunk-32
- unnamed-chunk-33
- unnamed-chunk-36
- unnamed-chunk-38
- unnamed-chunk-39
To ensure reproducibility of the results, delete the cache directory
featureSelection_cache and re-run the analysis. To have
workflowr automatically delete the cache directory prior to building the
file, set delete_cache = TRUE when running
wflow_build() or wflow_publish().
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Tracking code development and connecting the code version to the
results is critical for reproducibility. To start using Git, open the
Terminal and type git init in your project directory.
This project is not being versioned with Git. To obtain the full
reproducibility benefits of using workflowr, please see
?wflow_start.
Load packages
library(MultiAssayExperiment)
library(jyluMisc)
library(tidyverse)
knitr::opts_chunk$set(warning = FALSE, message = FALSE)Preprocessing datsets
Load data
load("../output/processedData.RData")Only use cancer samples
mae <- mae[,mae$condition!="noMalignancy"]CBA data
cbaMat <- mae[["cba"]]
cbaMat <- glog2(cbaMat)
mae[["cba"]] <- cbaMatNMR data
No transformation
nmrMat <- mae[["nmr"]]Create a new group with follow_up - baseline
CBA
cbaBase <- glog2(mae[,mae$condition == "Baseline"][["cba"]])
colnames(cbaBase) <- mae[,mae$condition == "Baseline"]$patID
cbaFollow <- glog2(mae[,mae$condition == "Follow_Up"][["cba"]])
colnames(cbaFollow) <- mae[,mae$condition == "Follow_Up"]$patID
allPat <- unique(c(colnames(cbaBase), colnames(cbaFollow)))
cbaDiff <- cbaFollow[,match(allPat,colnames(cbaFollow))] - cbaBase[,match(allPat,colnames(cbaBase))]
colnames(cbaDiff) <- allPat
cbaDiff <- cbaDiff[,complete.cases(t(cbaDiff))]NMR
nmrBase <- mae[,mae$condition == "Baseline"][["nmr"]]
colnames(nmrBase) <- mae[,mae$condition == "Baseline"]$patID
nmrFollow <- mae[,mae$condition == "Follow_Up"][["nmr"]]
colnames(nmrFollow) <- mae[,mae$condition == "Follow_Up"]$patID
allPat <- unique(c(colnames(nmrBase), colnames(nmrFollow)))
nmrDiff <- nmrFollow[,match(allPat,colnames(nmrFollow))] - nmrBase[,match(allPat,colnames(nmrBase))]
colnames(nmrDiff) <- allPat
nmrDiff <- nmrDiff[,complete.cases(t(nmrDiff))]Combine and create new mae object
matList <- list(cba = cbind(cbaMat, cbaDiff),
nmr = cbind(nmrMat, nmrDiff))
#create new annotation
diffPatAnno <- colData(mae[,mae$condition != "noMalignancy"])
diffPatAnno <- diffPatAnno[!duplicated(diffPatAnno$patID),]
diffPatAnno$condition <- "Follow_Up_Baseline_diff"
rownames(diffPatAnno) <- diffPatAnno$patID
diffPatAnno <- diffPatAnno[rownames(diffPatAnno) %in% c(colnames(cbaDiff), colnames(nmrDiff)),]
newColData <- rbind(colData(mae), diffPatAnno)[,c("patID","condition","Group")]
maeNew <- MultiAssayExperiment(matList, colData = newColData)Data completeness
plotTab <- colData(maeNew) %>% as_tibble() %>%
mutate(present = complete.cases(t(maeNew[["cba"]]))) %>%
filter(present)
ggplot(plotTab, aes(x=patID, y=condition, fill = present)) +
geom_tile(col="black") +
facet_wrap(~Group, scale = "free_x", ncol=1) +
theme_classic()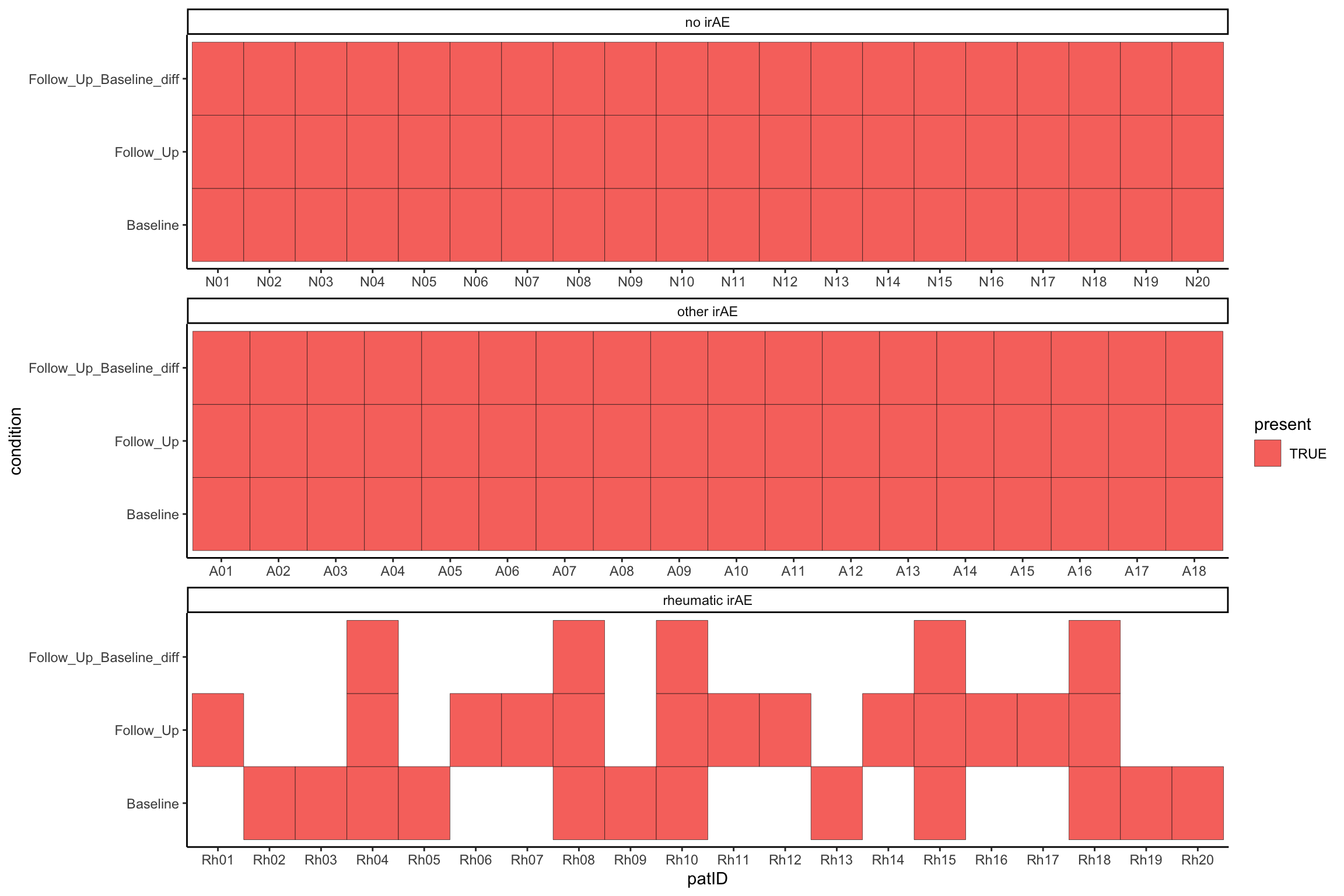
library(randomForest)
library(caret)Three group model
Use baseline data
Preprocessing
cbaMat <- mae[["cba"]][,mae$condition == "Baseline"]
nmrMat <- mae[["nmr"]][,mae$condition == "Baseline"]
X <- t(rbind(cbaMat, nmrMat))
y <- factor(mae[,rownames(X)]$Group)Random forest
#Create control function for training with 10 folds and keep 3 folds for training. search method is grid.
control <- trainControl(method='repeatedcv',
number=10,
repeats=10,
search='grid')
#create tunegrid with 15 values from 1:15 for mtry to tunning model. Our train function will change number of entry variable at each split according to tunegrid.
tunegrid <- expand.grid(.mtry = (5:20))
rf_gridsearch <- train(X, y,
method = 'rf',
metric = 'Accuracy',
#tuneGrid = tunegrid,
tuneLength = 10,
ntree = 1000)
#print(rf_gridsearch)
plot(rf_gridsearch)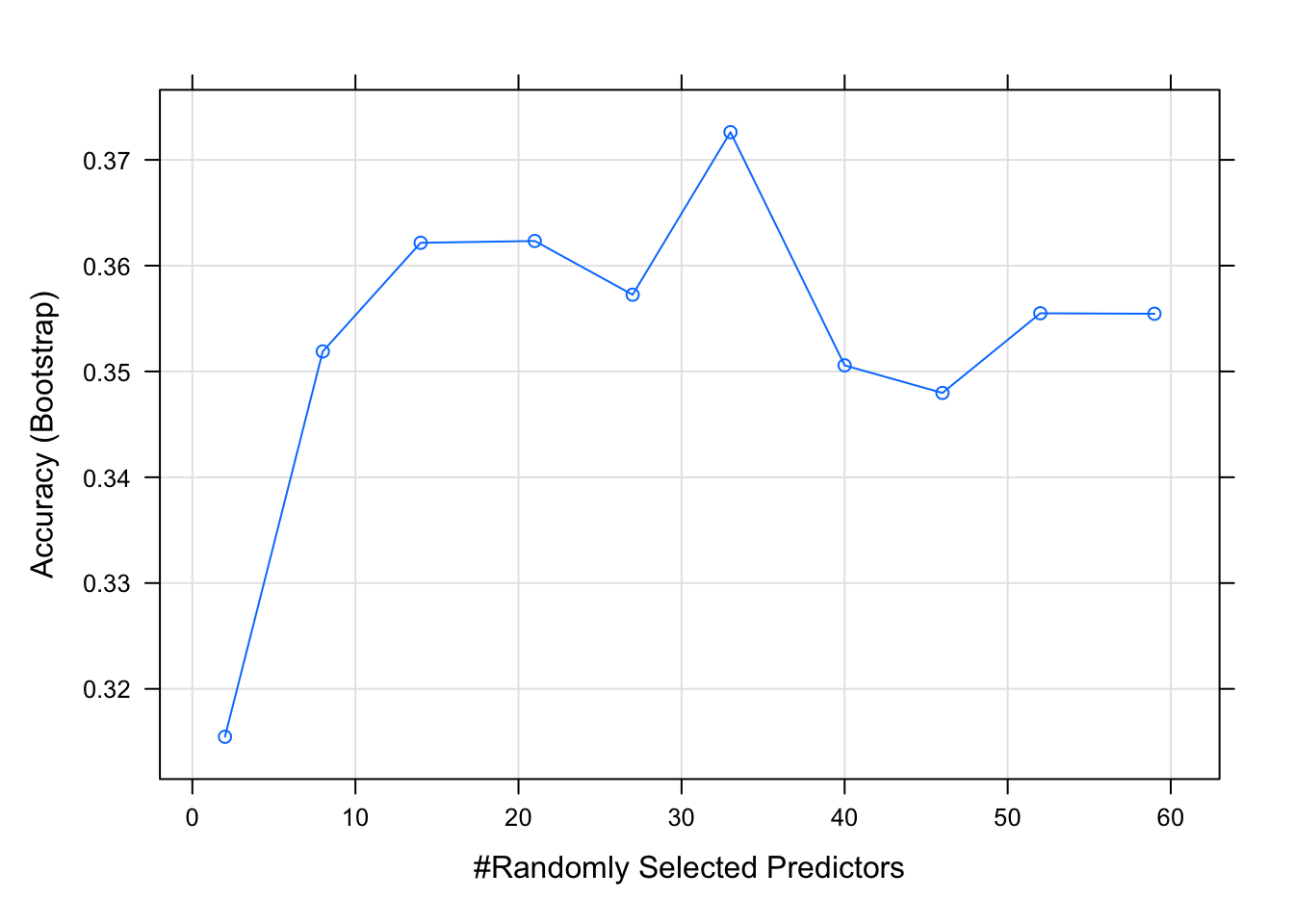
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
varImpPlot(rf_gridsearch$finalModel)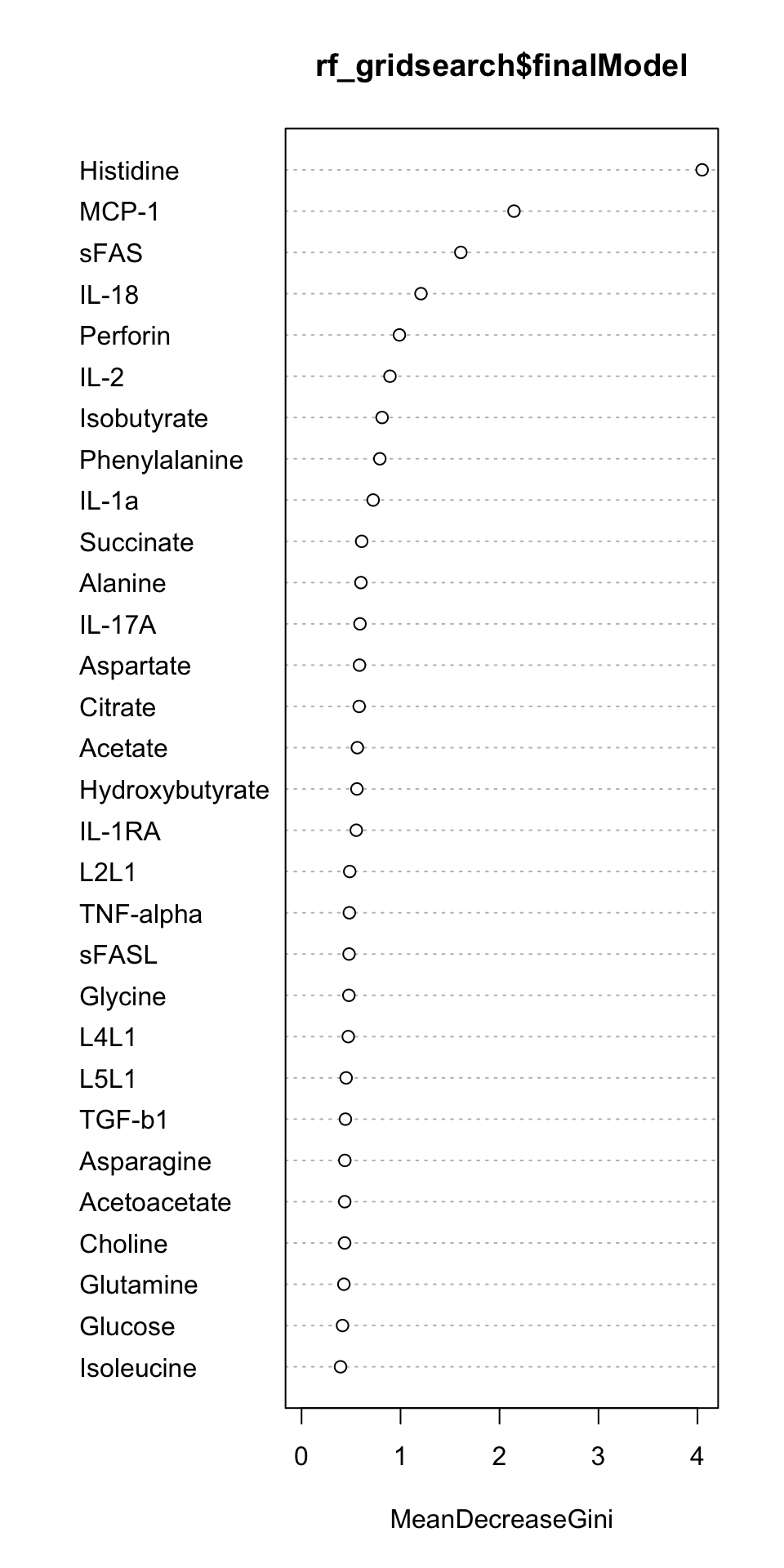
SVM with non-linear kernel
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
# Fit the model
svms <- train(X, y, method = "svmRadial",
trControl = train_control,
preProcess = c("center","scale"),
tuneLength = 10)
# Print the best tuning parameter sigma and C that maximizes model accuracy
svms$bestTune sigma C
1 0.01009869 0.25plot(svms)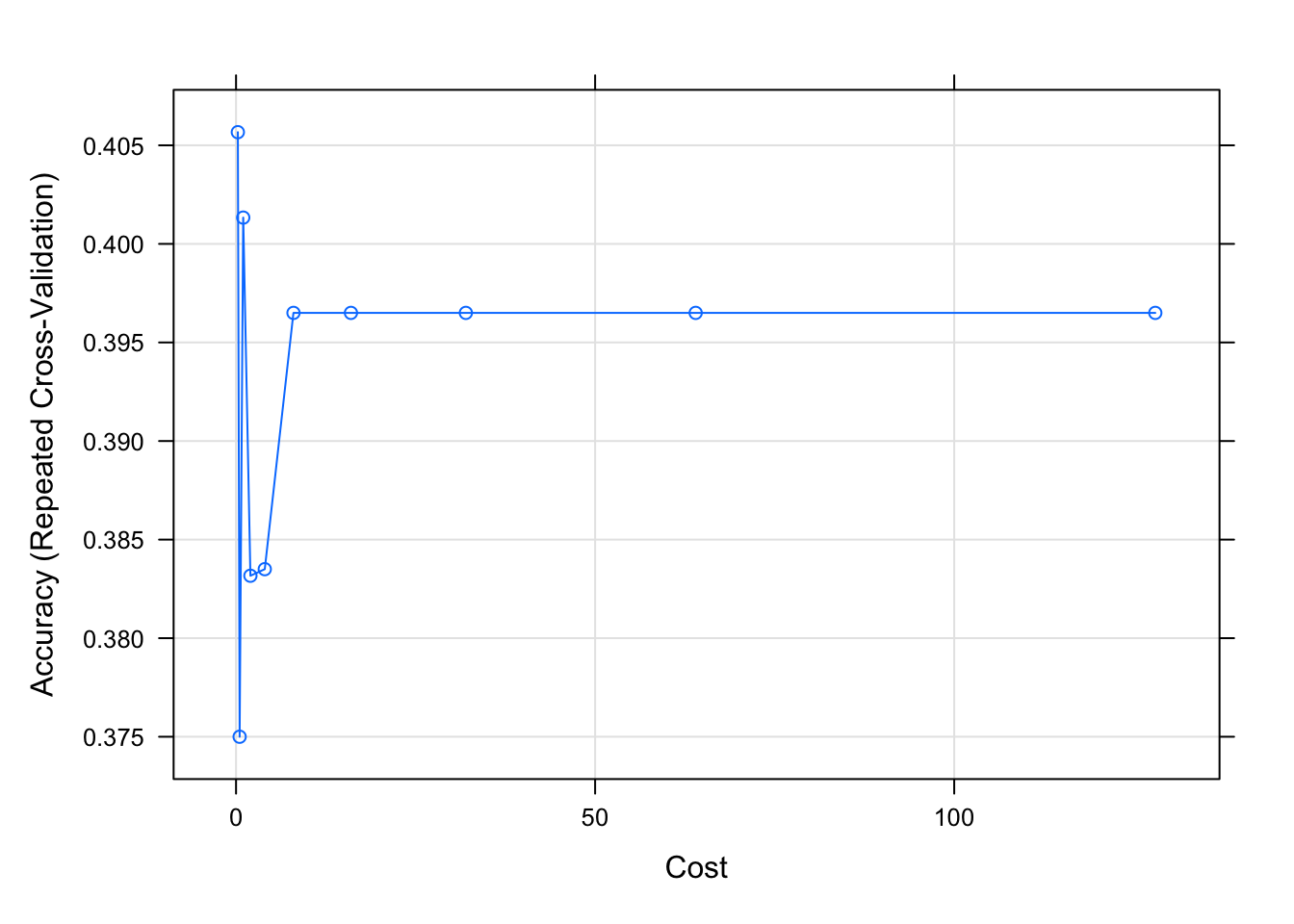
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Multi-nomial regression (Elastic net)
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
net.fit = train(X, y,
method="glmnet",
trControl=train_control,
metric = "Accuracy",
tuneLength = 10,
preProcess = c("center","scale"),
family="multinomial")
plot(net.fit)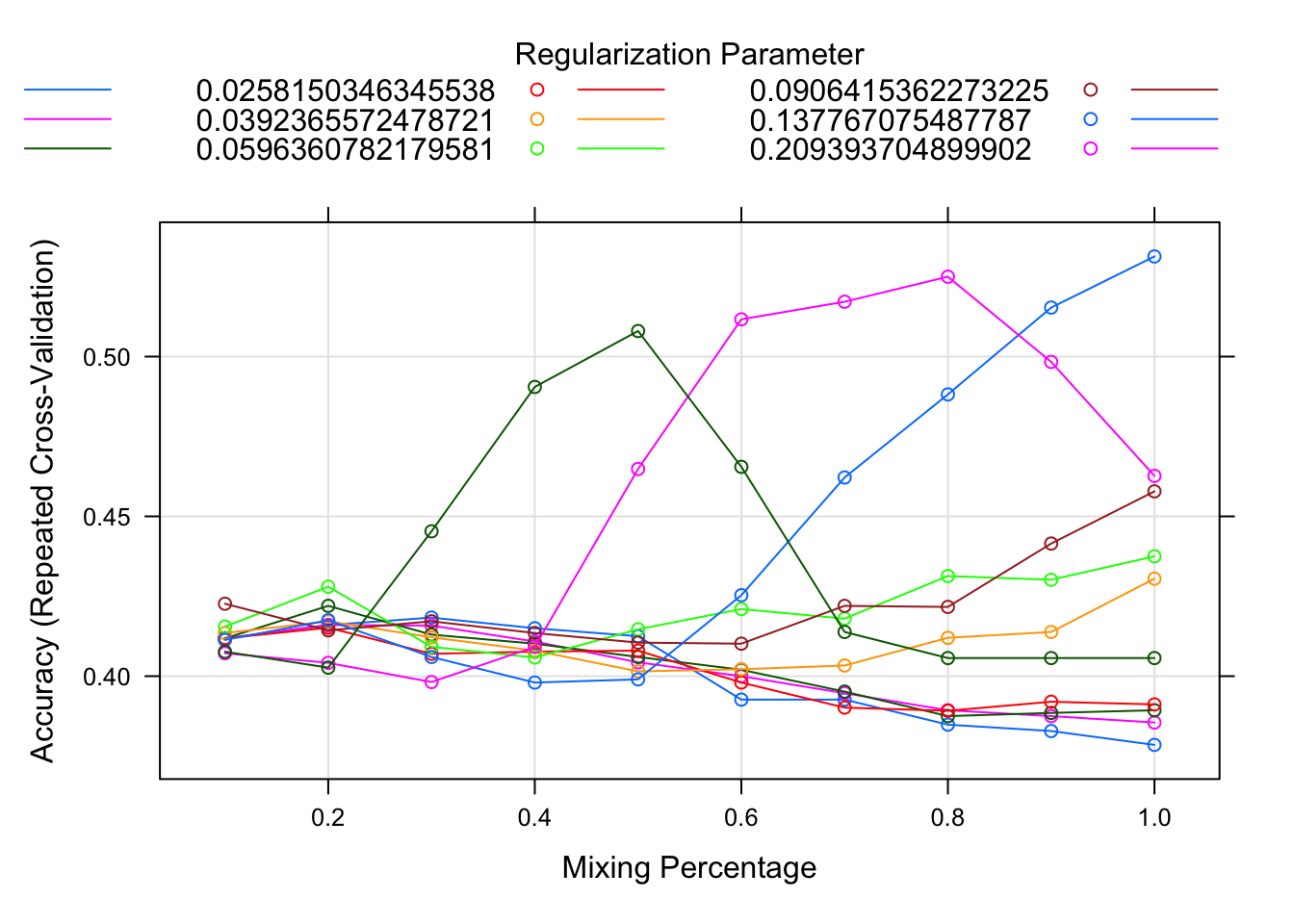
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
impTab <- varImp(net.fit$finalModel)
impTab <- impTab[rowSums(impTab)>0,] %>%
as_tibble(rownames = "feature") %>%
pivot_longer(-feature, names_to = "group", values_to = "coef") %>%
arrange(desc(abs(coef))) %>%
mutate(feature = factor(feature, levels = unique(feature)))
ggplot(impTab, aes(x=feature, y=coef, fill = group)) +
geom_bar(stat = "identity", position = "dodge", width = .5) +
theme(axis.text.x = element_text(angle = 90, hjust = 1 , vjust=0.5))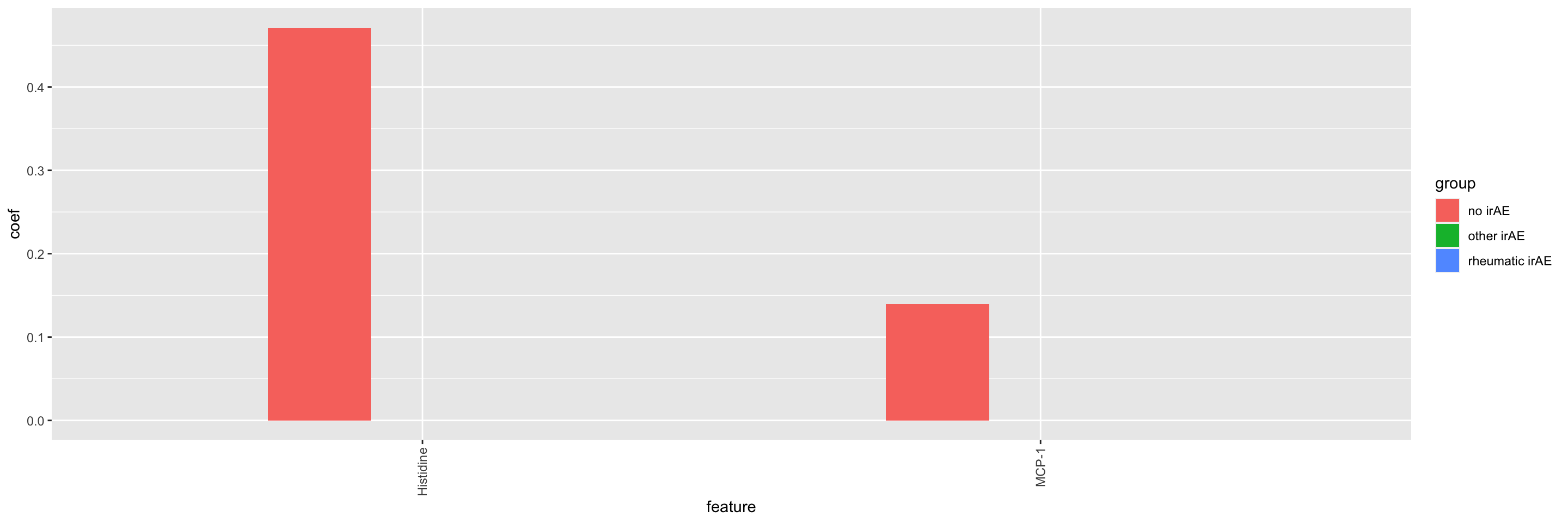
Use follw_up data
Preprocessing
cbaMat <- mae[["cba"]][,mae$condition == "Follow_Up"]
nmrMat <- mae[["nmr"]][,mae$condition == "Follow_Up"]
X <- t(rbind(cbaMat, nmrMat))
y <- factor(mae[,rownames(X)]$Group)Random forest
#Create control function for training with 10 folds and keep 3 folds for training. search method is grid.
control <- trainControl(method='repeatedcv',
number=10,
repeats=10,
search='grid')
#create tunegrid with 15 values from 1:15 for mtry to tunning model. Our train function will change number of entry variable at each split according to tunegrid.
tunegrid <- expand.grid(.mtry = (5:20))
rf_gridsearch <- train(X, y,
method = 'rf',
metric = 'Accuracy',
#tuneGrid = tunegrid,
tuneLength = 10,
#preProcess = c("center","scale"),
ntree = 1000)
#print(rf_gridsearch)
plot(rf_gridsearch)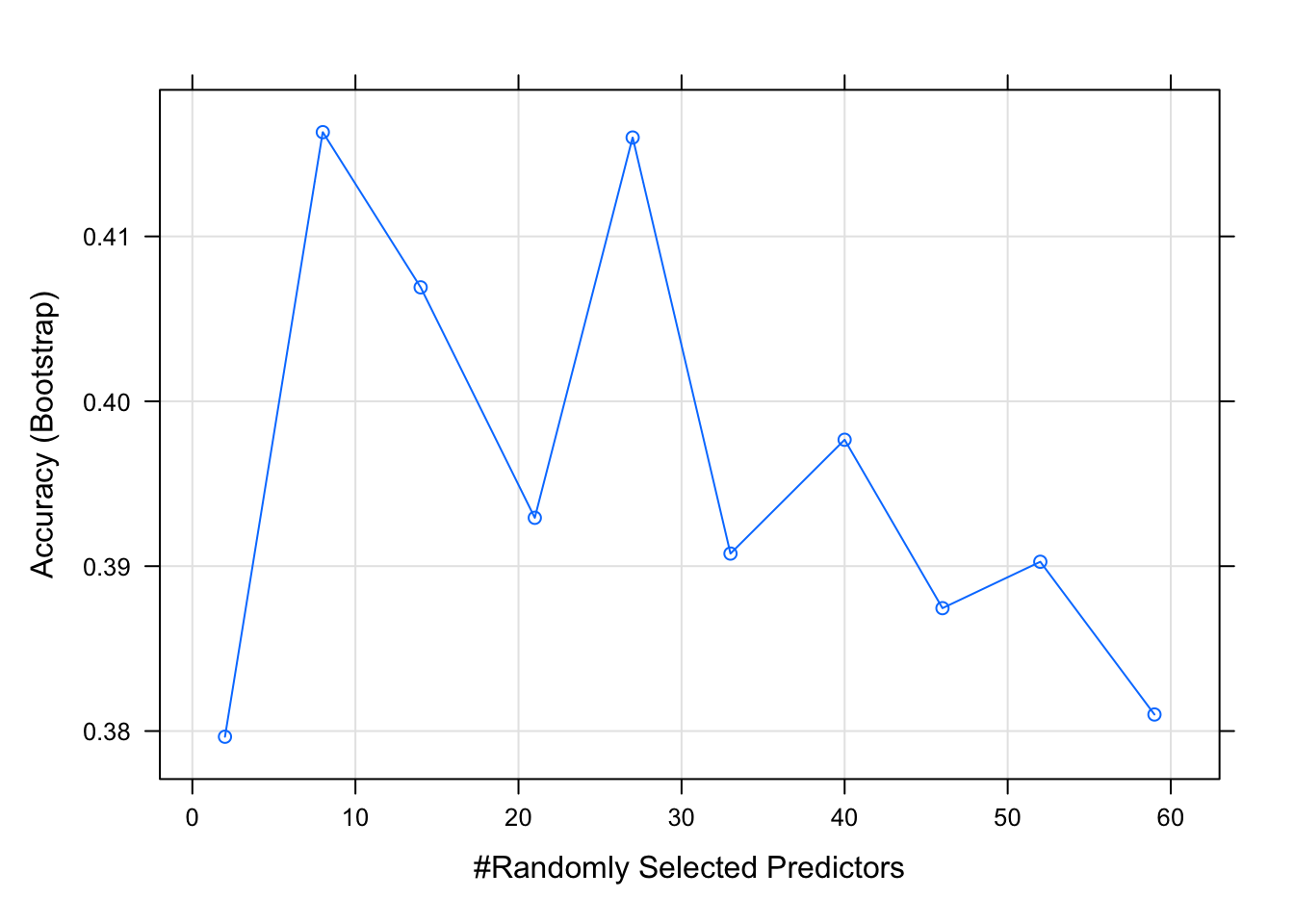
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
varImpPlot(rf_gridsearch$finalModel)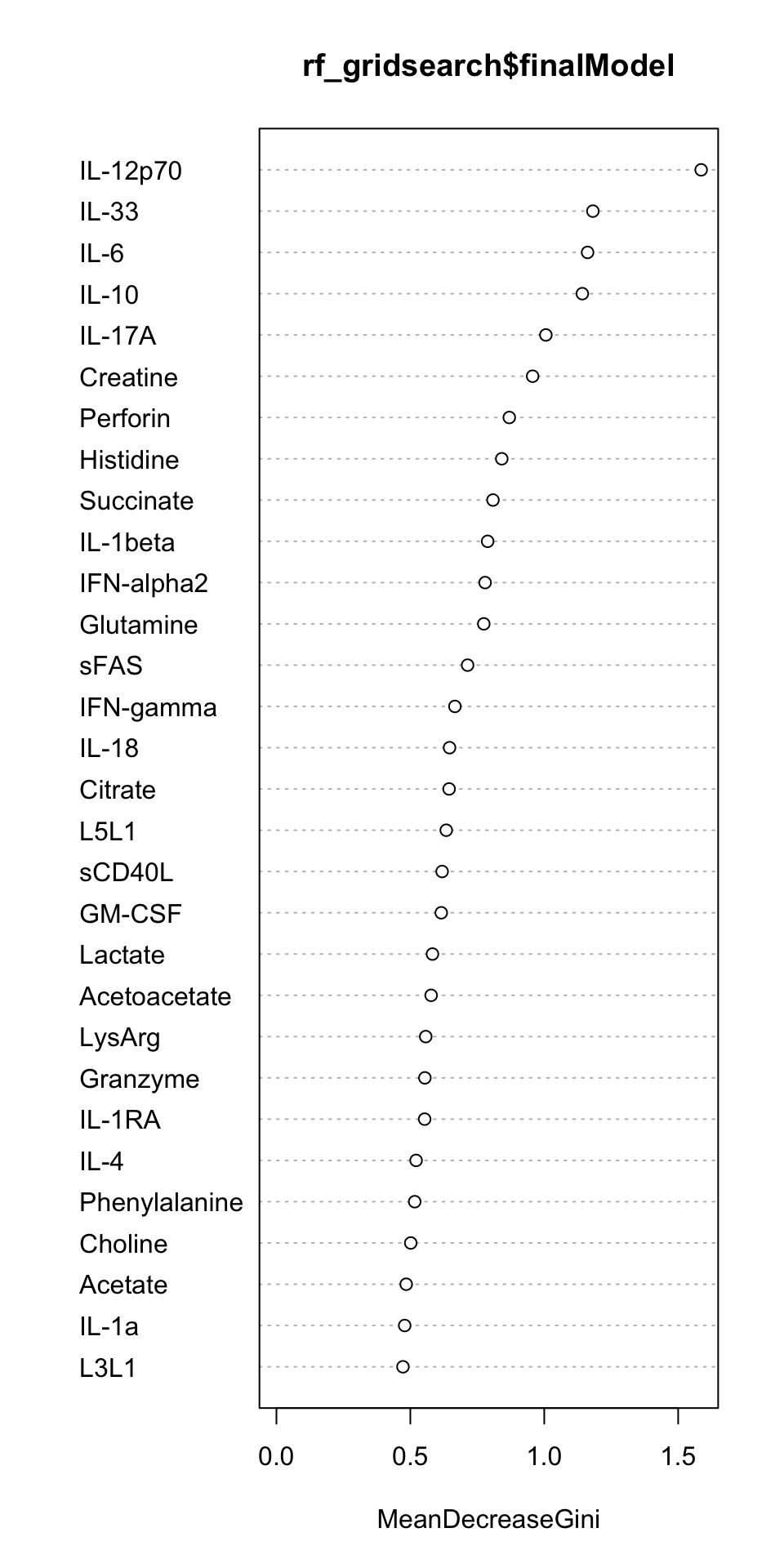
SVM with non-linear kernel
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
# Fit the model
svms <- train(X, y, method = "svmRadial",
trControl = train_control,
preProcess = c("center","scale"),
tuneLength = 10)
# Print the best tuning parameter sigma and C that maximizes model accuracy
svms$bestTune sigma C
6 0.01210822 8plot(svms)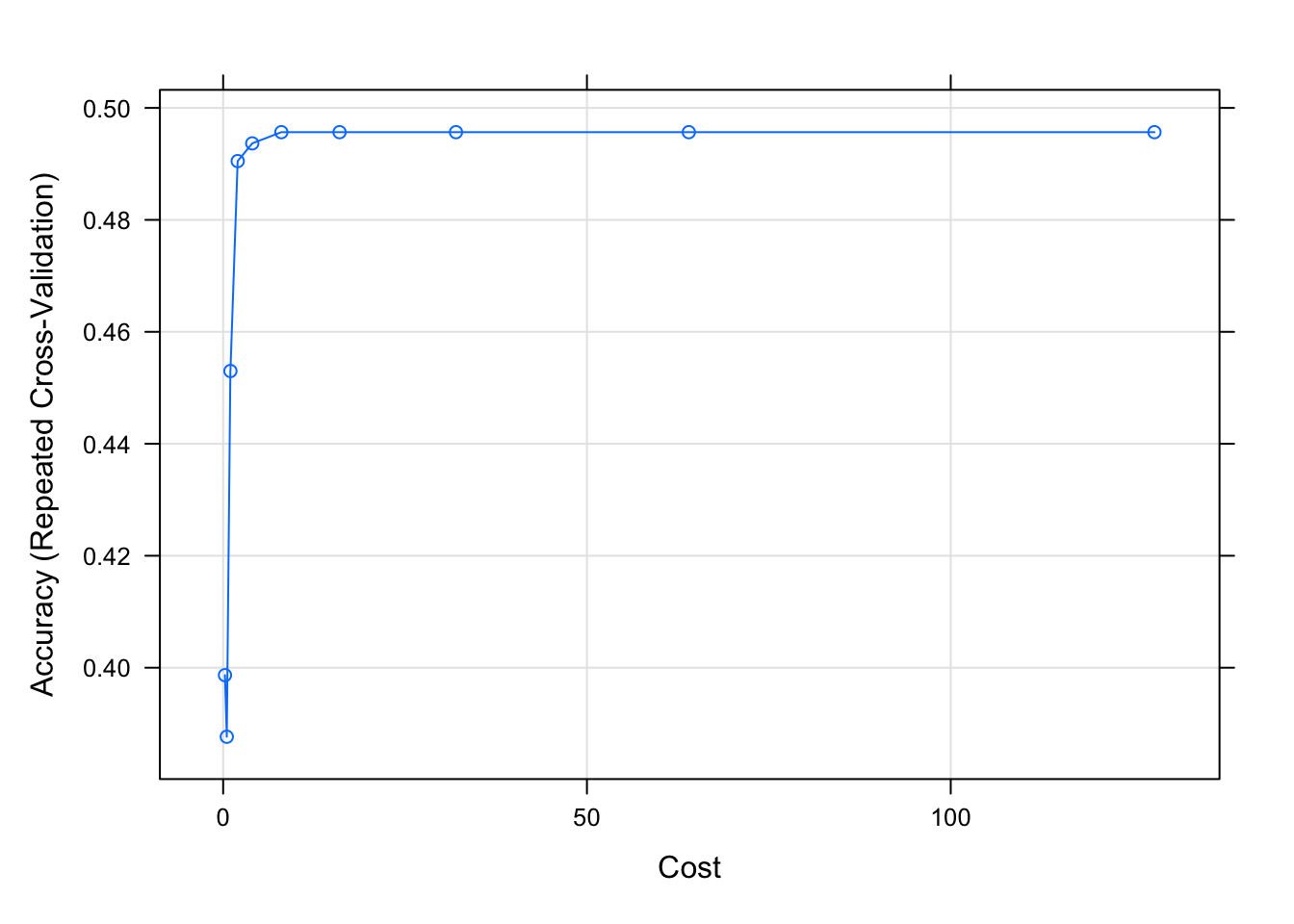
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Multi-nomial regression (Elastic net)
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
net.fit = train(X, y,
method="glmnet",
trControl=train_control,
metric = "Accuracy",
tuneLength = 10,
preProcess = c("center","scale"),
family="multinomial")
plot(net.fit)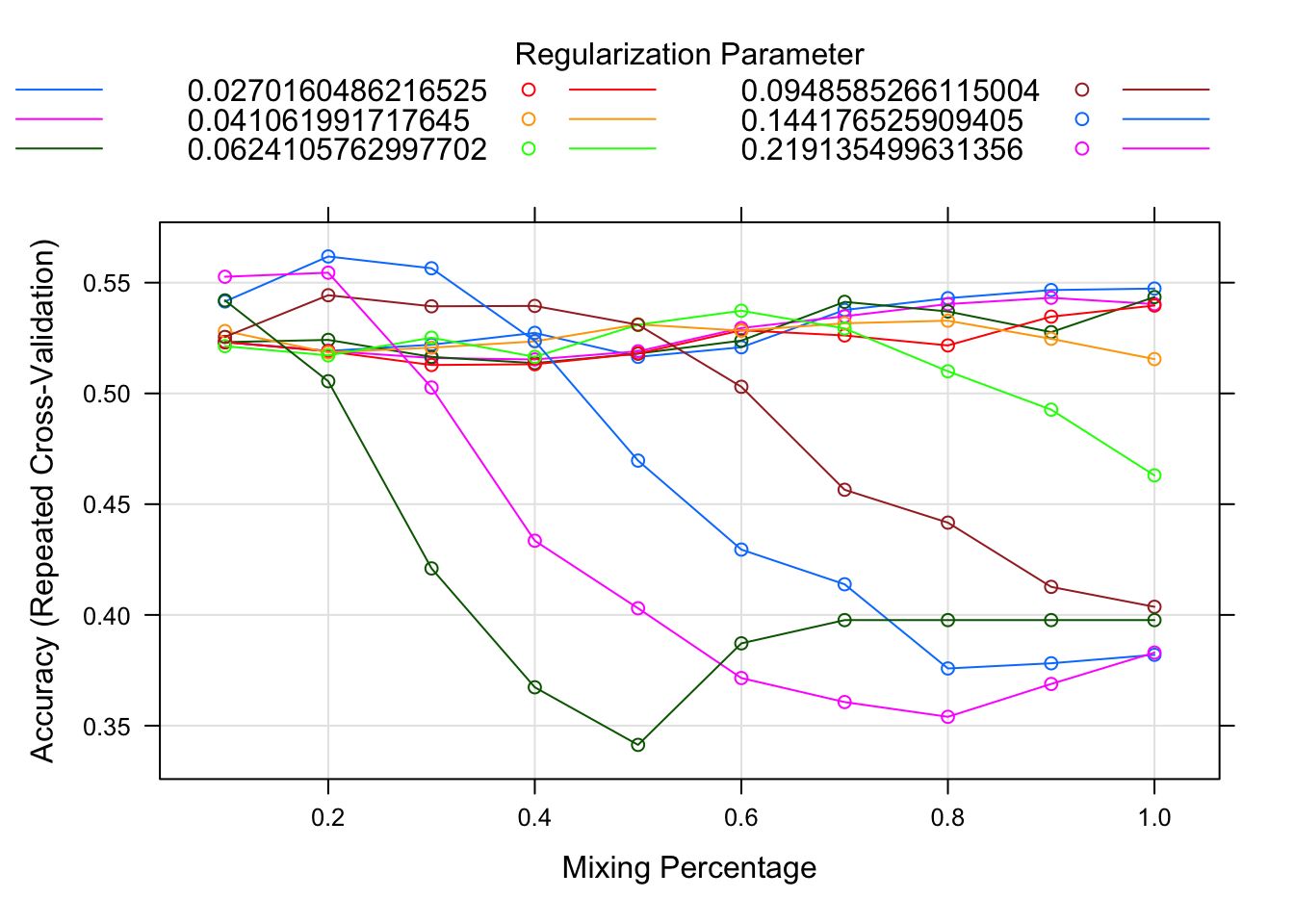
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
impTab <- varImp(net.fit$finalModel)
impTab <- impTab[rowSums(impTab)>0,] %>%
as_tibble(rownames = "feature") %>%
pivot_longer(-feature, names_to = "group", values_to = "coef") %>%
arrange(desc(abs(coef))) %>%
mutate(feature = factor(feature, levels = unique(feature)))
ggplot(impTab, aes(x=feature, y=coef, fill = group)) +
geom_bar(stat = "identity", position = "dodge", width = .5) +
theme(axis.text.x = element_text(angle = 90, hjust = 1 , vjust=0.5))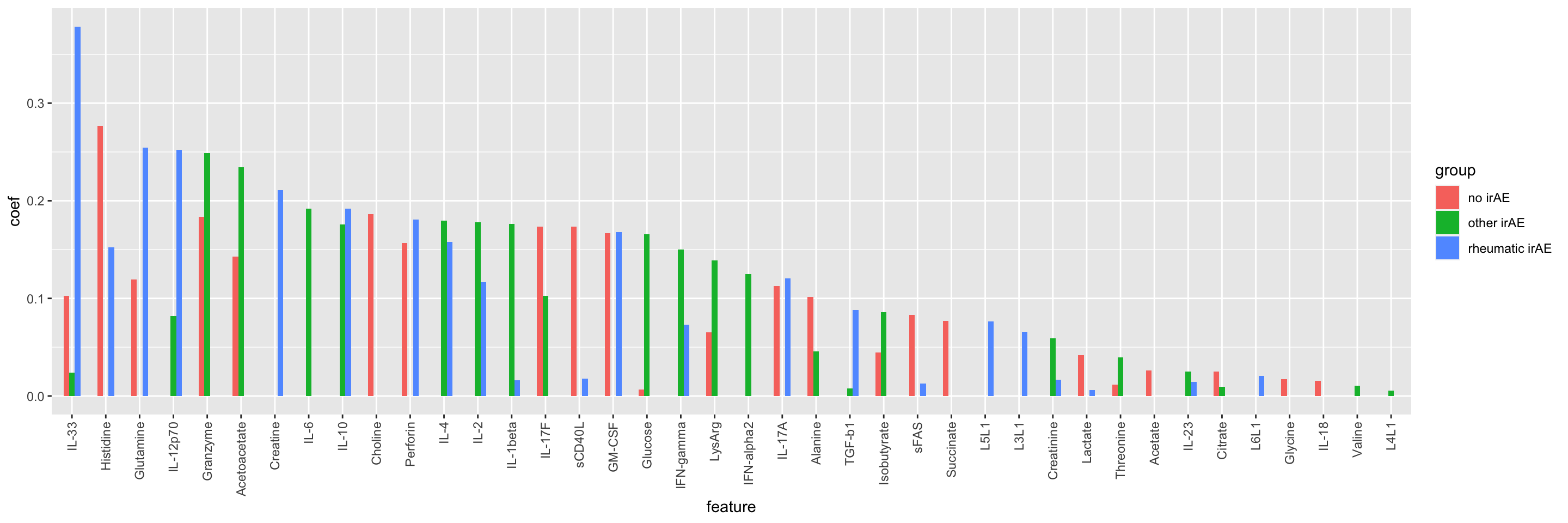
Two group model (combine rheumatic irAE and other irAE into one irAE group)
Use baseline data
Preprocessing
cbaMat <- mae[["cba"]][,mae$condition == "Baseline"]
nmrMat <- mae[["nmr"]][,mae$condition == "Baseline"]
mae$Group2 <- ifelse(mae$Group == "no irAE", mae$Group, "irAE")
X <- t(rbind(cbaMat, nmrMat))
y <- factor(mae[,rownames(X)]$Group2)Random forest
#Create control function for training with 10 folds and keep 3 folds for training. search method is grid.
control <- trainControl(method='repeatedcv',
number=10,
repeats=10,
search='grid')
#create tunegrid with 15 values from 1:15 for mtry to tunning model. Our train function will change number of entry variable at each split according to tunegrid.
tunegrid <- expand.grid(.mtry = (5:20))
rf_gridsearch <- train(X, y,
method = 'rf',
metric = 'Accuracy',
tuneGrid = tunegrid,
ntree = 1000)
#print(rf_gridsearch)
plot(rf_gridsearch)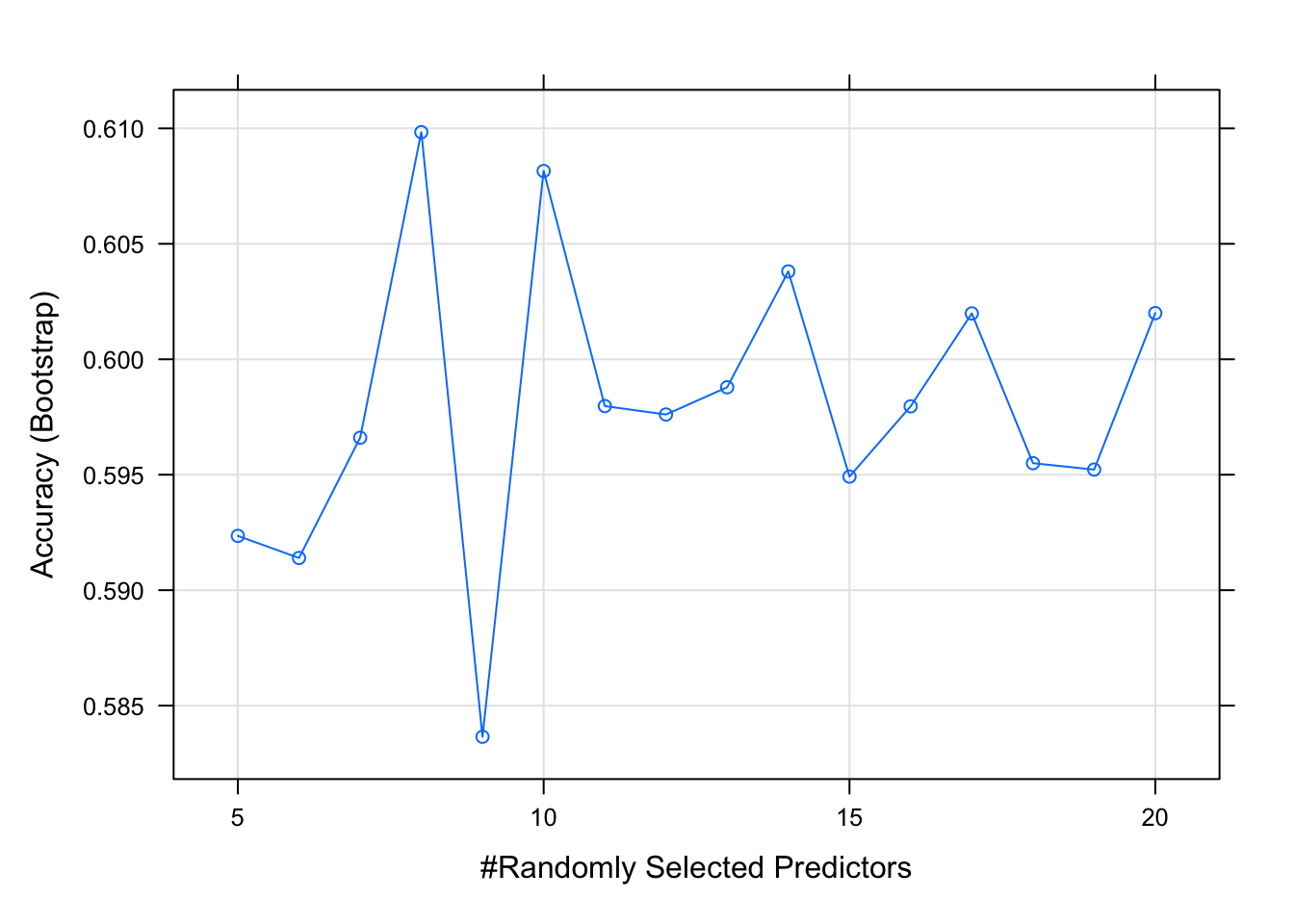
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
varImpPlot(rf_gridsearch$finalModel)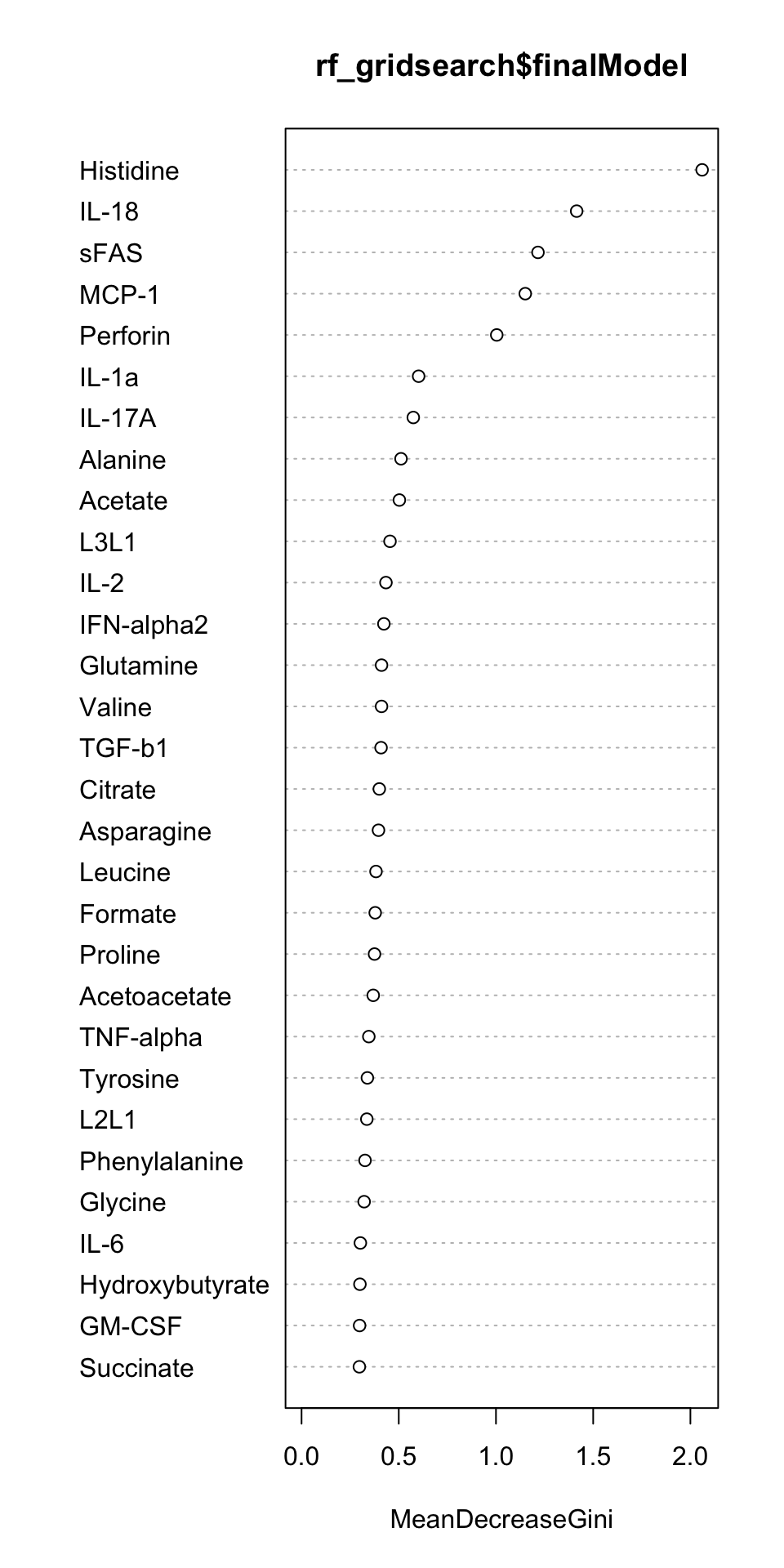
SVM with non-linear kernel
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
# Fit the model
svms <- train(X, y, method = "svmRadial",
trControl = train_control,
preProcess = c("center","scale"),
tuneLength = 10)
# Print the best tuning parameter sigma and C that maximizes model accuracy
svms$bestTune sigma C
4 0.01034465 2plot(svms)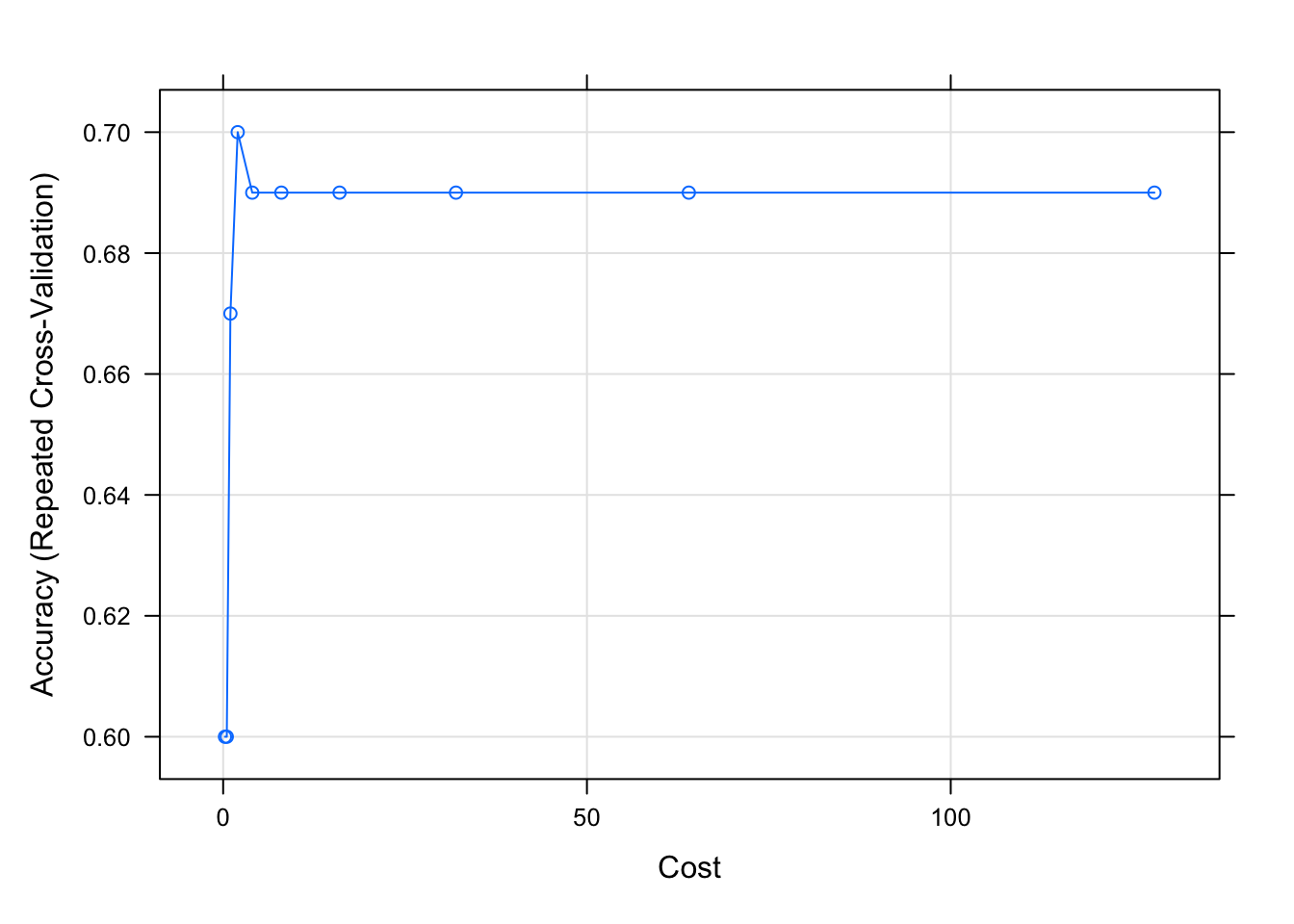
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Logistic regression (Elastic net)
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
net.fit = train(X, y,
method="glmnet",
trControl=train_control,
metric = "Accuracy",
tuneLength = 10,
preProcess = c("center","scale"),
family="binomial")
plot(net.fit)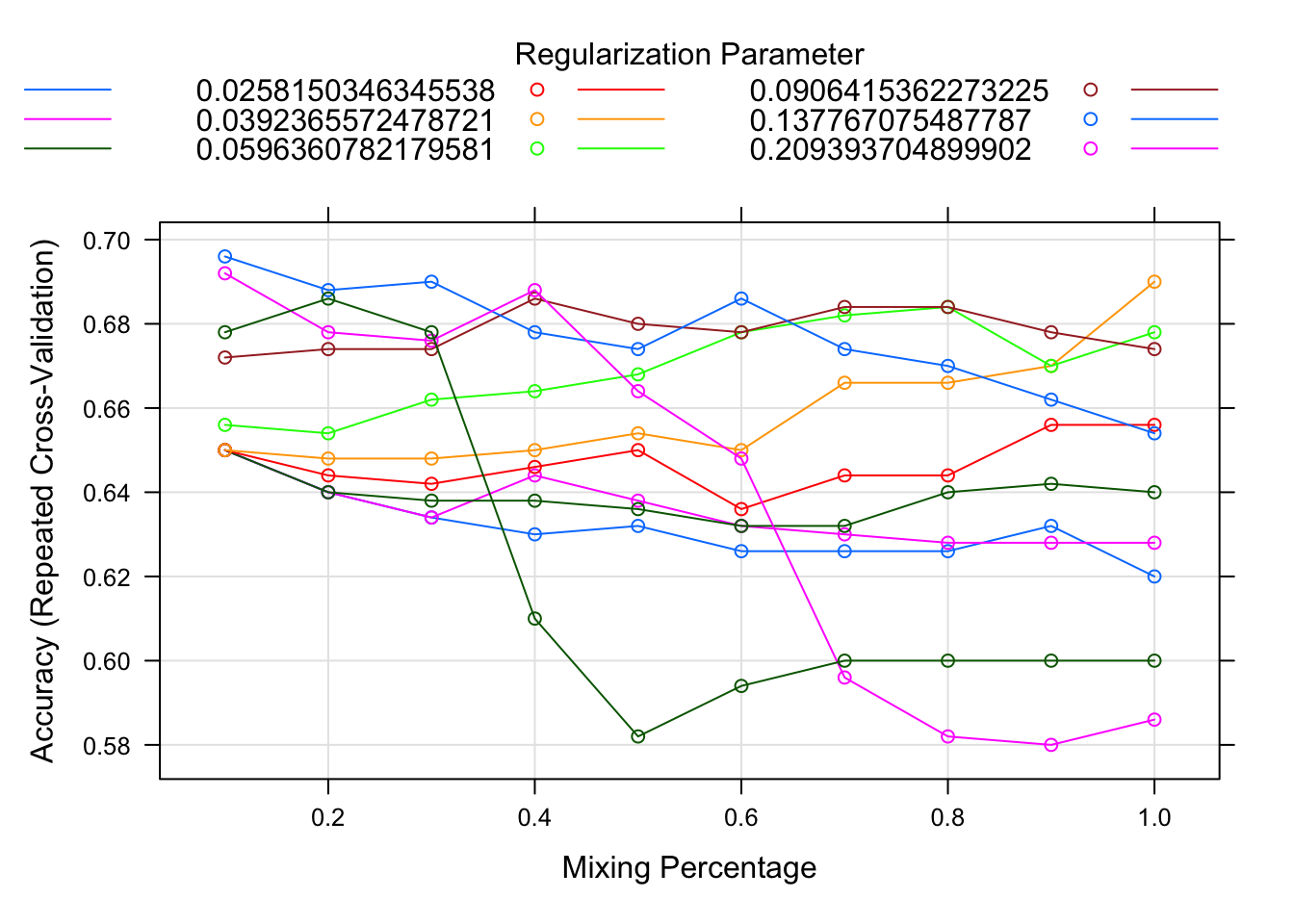
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
impTab <- varImp(net.fit$finalModel)
impTab <- impTab[rowSums(impTab)>0,,drop=FALSE] %>%
as_tibble(rownames = "feature") %>%
pivot_longer(-feature, names_to = "group", values_to = "coef") %>%
arrange(desc(abs(coef))) %>%
mutate(feature = factor(feature, levels = unique(feature)))
ggplot(impTab, aes(x=feature, y=coef, fill = group)) +
geom_bar(stat = "identity", position = "dodge", width = .5) +
theme(axis.text.x = element_text(angle = 90, hjust = 1 , vjust=0.5))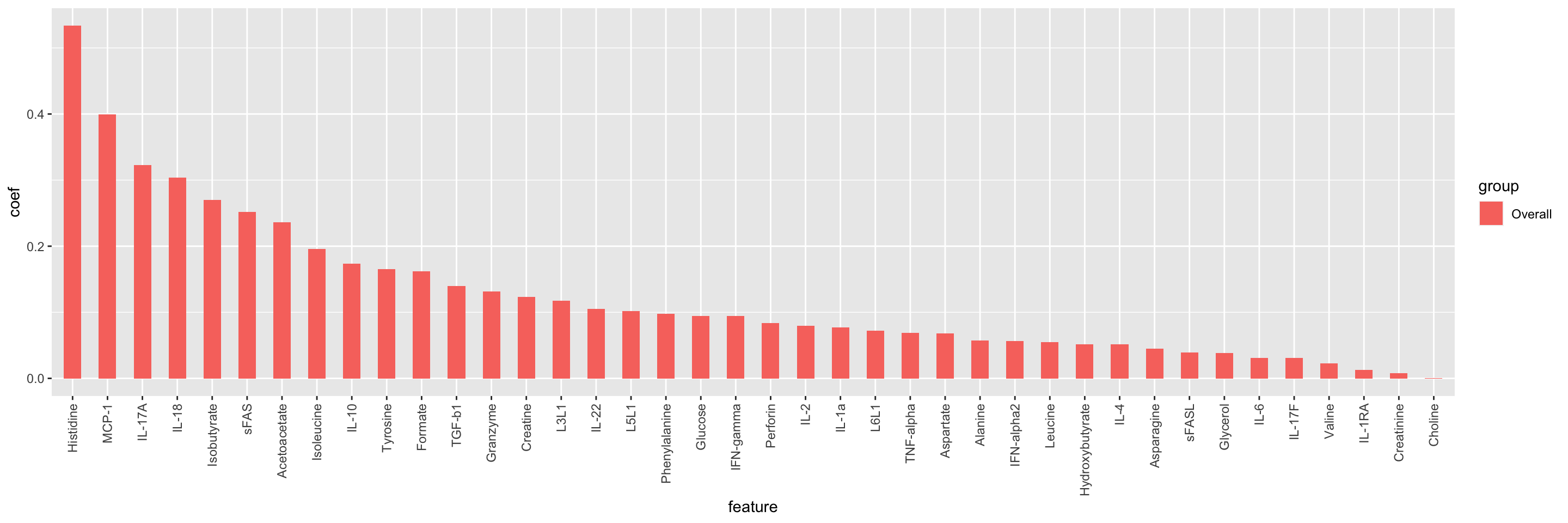
Use follw_up data
Preprocessing
cbaMat <- mae[["cba"]][,mae$condition == "Follow_Up"]
nmrMat <- mae[["nmr"]][,mae$condition == "Follow_Up"]
X <- t(rbind(cbaMat, nmrMat))
y <- factor(mae[,rownames(X)]$Group2)Random forest
#Create control function for training with 10 folds and keep 3 folds for training. search method is grid.
control <- trainControl(method='repeatedcv',
number=10,
repeats=10,
search='grid')
#create tunegrid with 15 values from 1:15 for mtry to tunning model. Our train function will change number of entry variable at each split according to tunegrid.
tunegrid <- expand.grid(.mtry = (5:20))
rf_gridsearch <- train(X, y,
method = 'rf',
metric = 'Accuracy',
tuneGrid = tunegrid,
#preProcess = c("center","scale"),
ntree = 1000)
#print(rf_gridsearch)
plot(rf_gridsearch)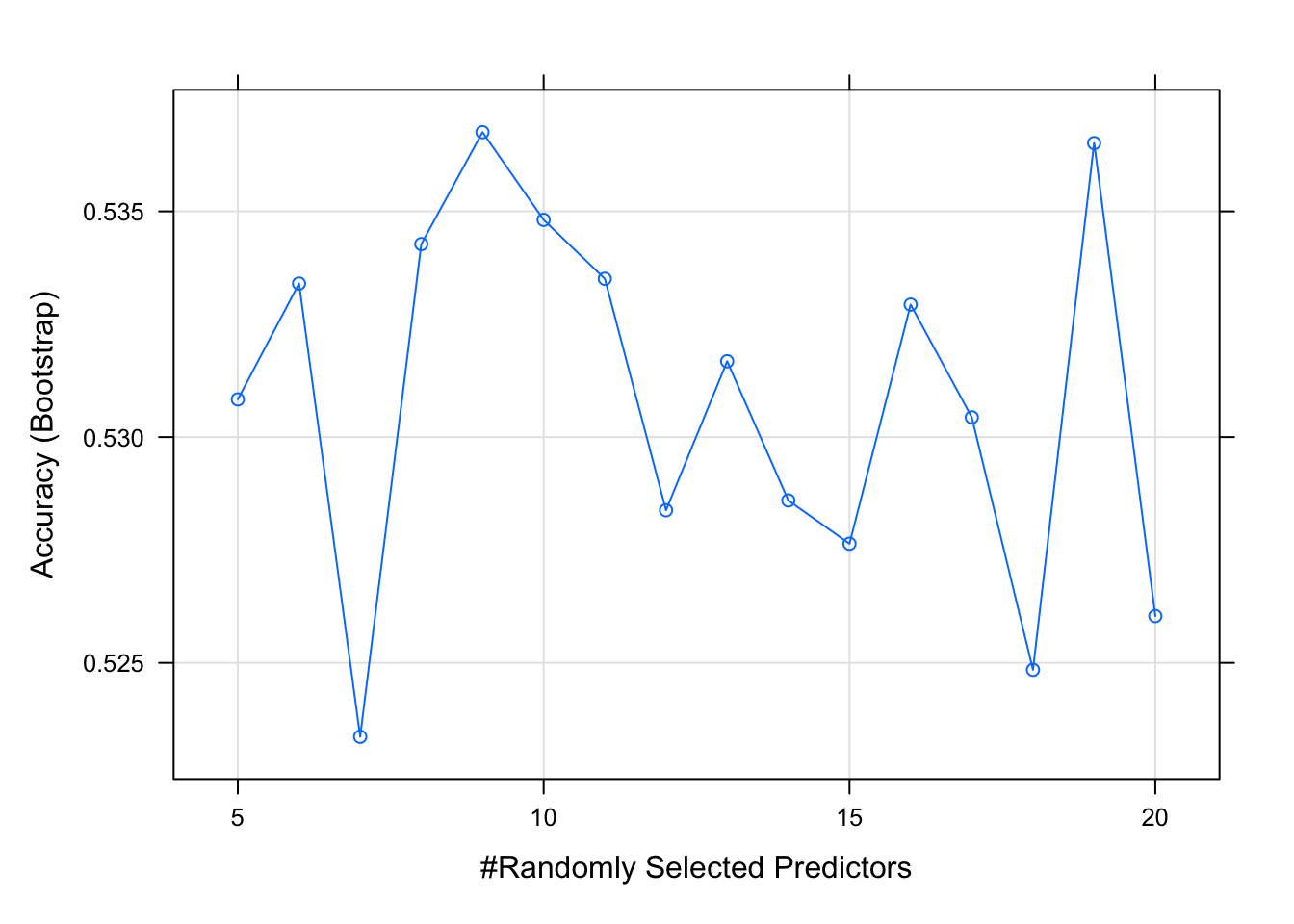
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
varImpPlot(rf_gridsearch$finalModel)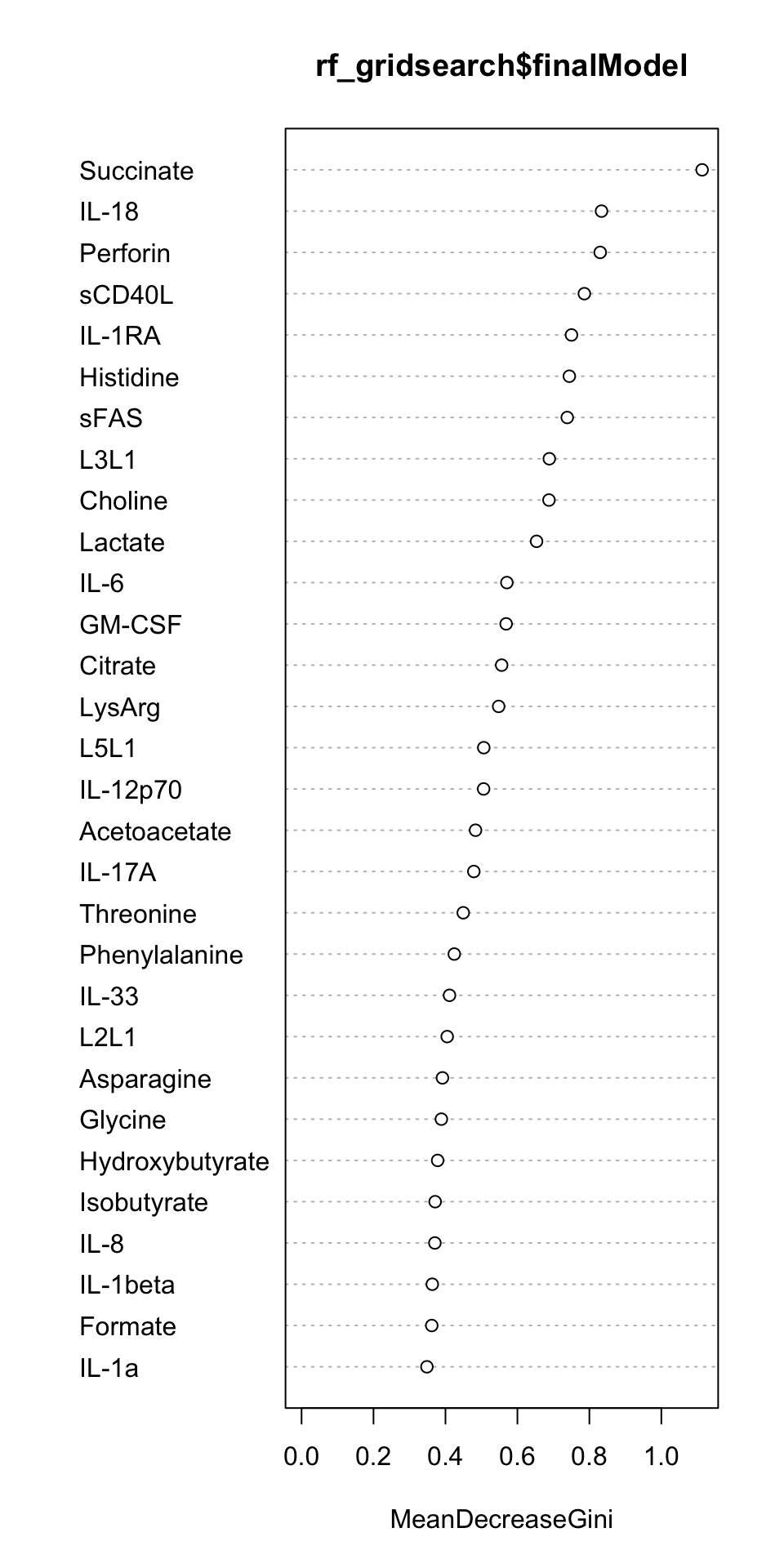
SVM with non-linear kernel
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
# Fit the model
svms <- train(X, y, method = "svmRadial",
trControl = train_control,
preProcess = c("center","scale"),
tuneLength = 10)
# Print the best tuning parameter sigma and C that maximizes model accuracy
svms$bestTune sigma C
6 0.01188517 8plot(svms)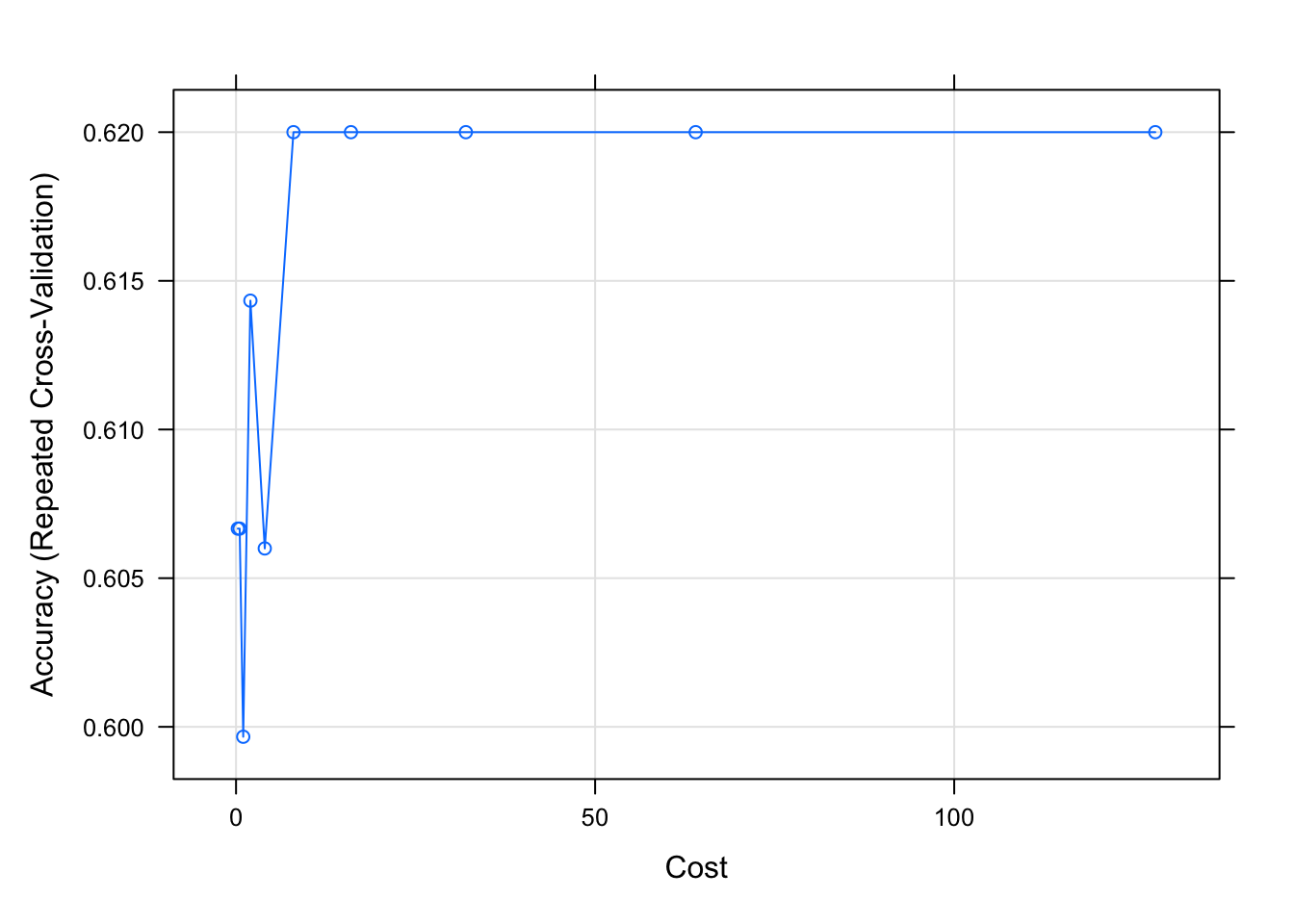
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Multi-nomial regression (Elastic net)
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
net.fit = train(X, y,
method="glmnet",
trControl=train_control,
metric = "Accuracy",
tuneLength = 10,
preProcess = c("center","scale"),
family="binomial")
plot(net.fit)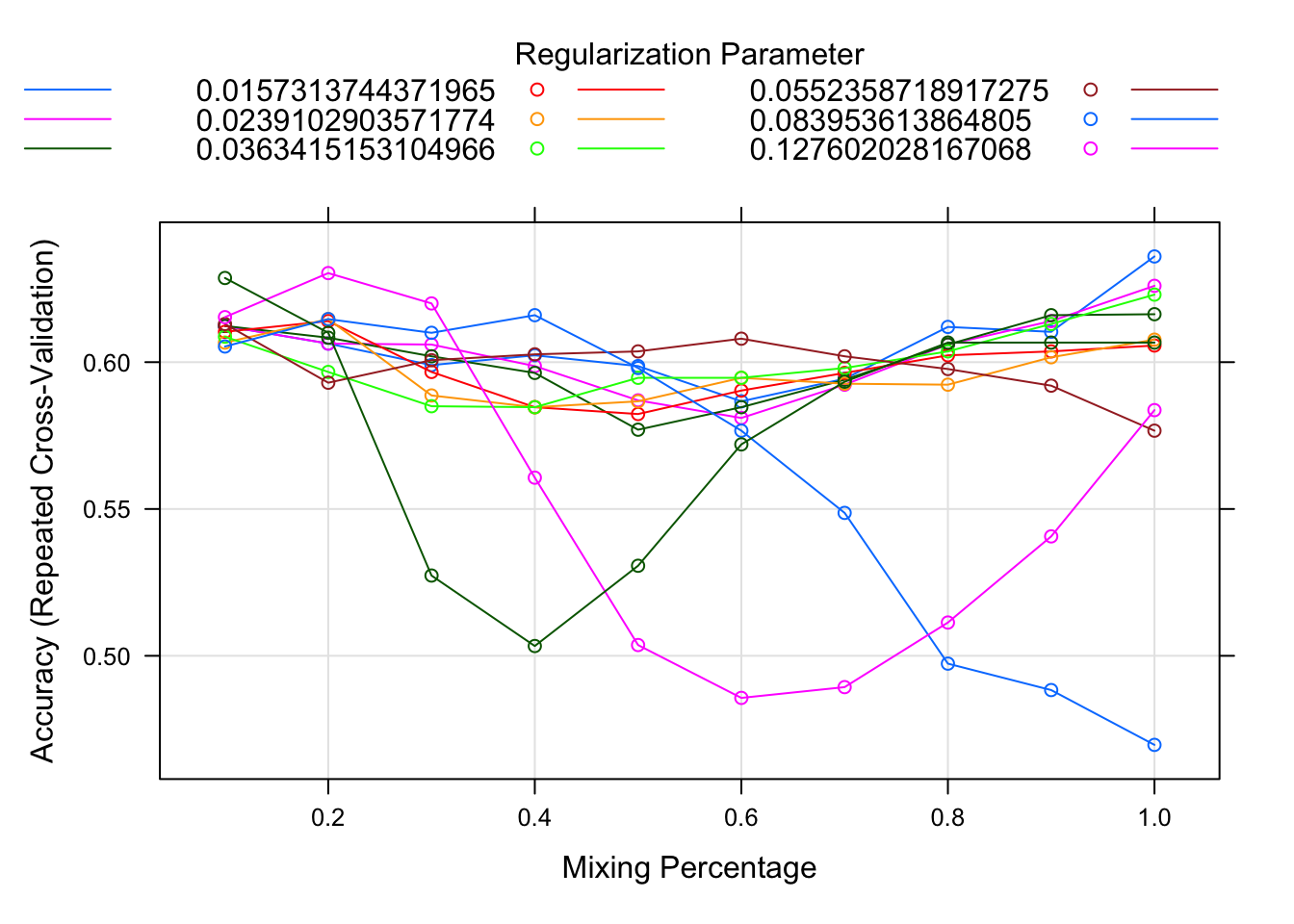
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
impTab <- varImp(net.fit$finalModel)
impTab <- impTab[rowSums(impTab)>0,,drop=FALSE] %>%
as_tibble(rownames = "feature") %>%
pivot_longer(-feature, names_to = "group", values_to = "coef") %>%
arrange(desc(abs(coef))) %>%
mutate(feature = factor(feature, levels = unique(feature)))
ggplot(impTab, aes(x=feature, y=coef, fill = group)) +
geom_bar(stat = "identity", position = "dodge", width = .5) +
theme(axis.text.x = element_text(angle = 90, hjust = 1 , vjust=0.5))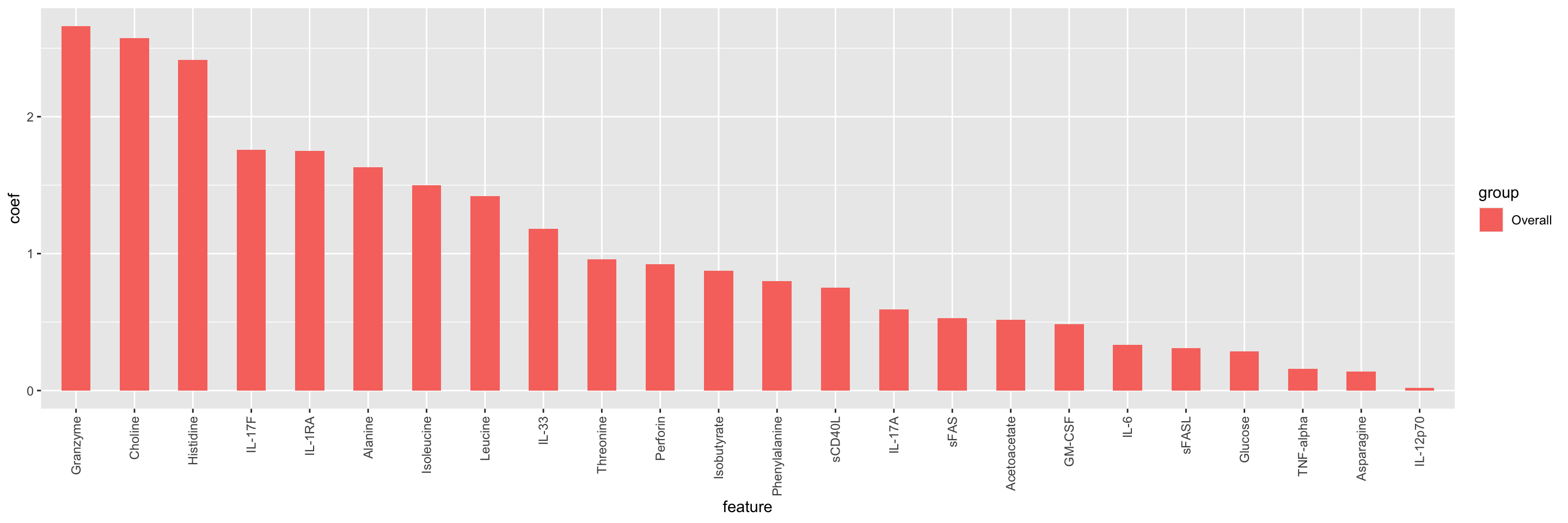
Combine follow_up, Baseline and Difference
Preprocessing
cbaMat <- maeNew[["cba"]] %>%
as_tibble(rownames = "feature") %>%
pivot_longer(-feature) %>%
mutate(condition = colData(maeNew)[name,]$condition,
patID = colData(maeNew)[name,]$patID) %>%
mutate(feature = paste0(feature,"_",condition)) %>%
select(feature, patID, value) %>%
pivot_wider(names_from = feature, values_from = value) %>%
column_to_rownames("patID") %>% as.matrix()
nmrMat <- maeNew[["nmr"]] %>%
as_tibble(rownames = "feature") %>%
pivot_longer(-feature) %>%
mutate(condition = colData(maeNew)[name,]$condition,
patID = colData(maeNew)[name,]$patID) %>%
mutate(feature = paste0(feature,"_",condition)) %>%
select(feature, patID, value) %>%
pivot_wider(names_from = feature, values_from = value) %>%
column_to_rownames("patID") %>% as.matrix()
X <- cbind(cbaMat, nmrMat)
X <- X[complete.cases(X),]
y <- factor(mae[,match(rownames(X), mae$patID)]$Group2)Random forest
#Create control function for training with 10 folds and keep 3 folds for training. search method is grid.
control <- trainControl(method='repeatedcv',
number=10,
repeats=10,
search='grid')
#create tunegrid with 15 values from 1:15 for mtry to tunning model. Our train function will change number of entry variable at each split according to tunegrid.
tunegrid <- expand.grid(.mtry = (15:50))
rf_gridsearch <- train(X, y,
method = 'rf',
metric = 'Accuracy',
tuneLength = 10,
#tuneGrid = tunegrid,
#preProcess = c("center","scale"),
ntree = 1000)
#print(rf_gridsearch)
plot(rf_gridsearch)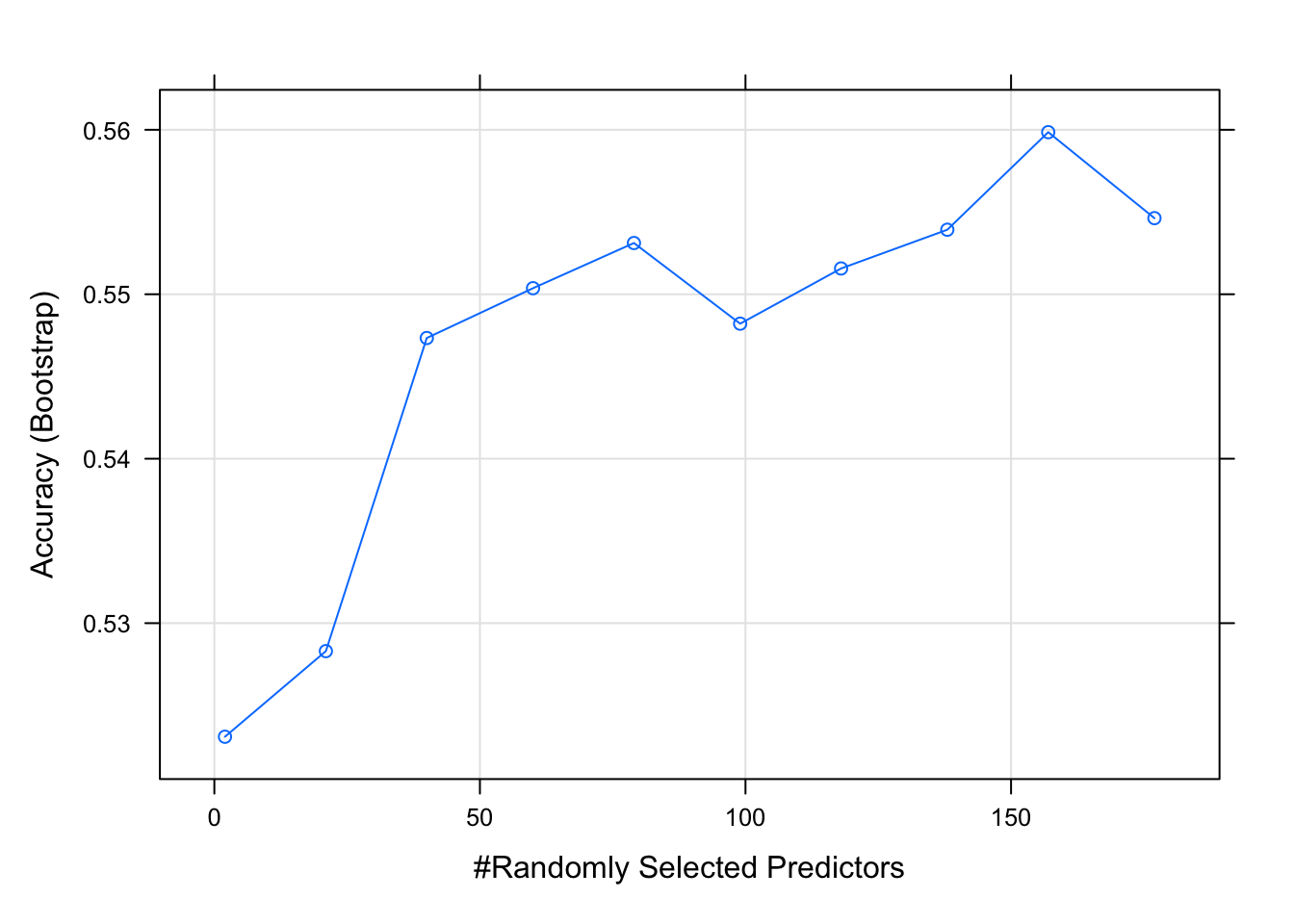
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
varImpPlot(rf_gridsearch$finalModel)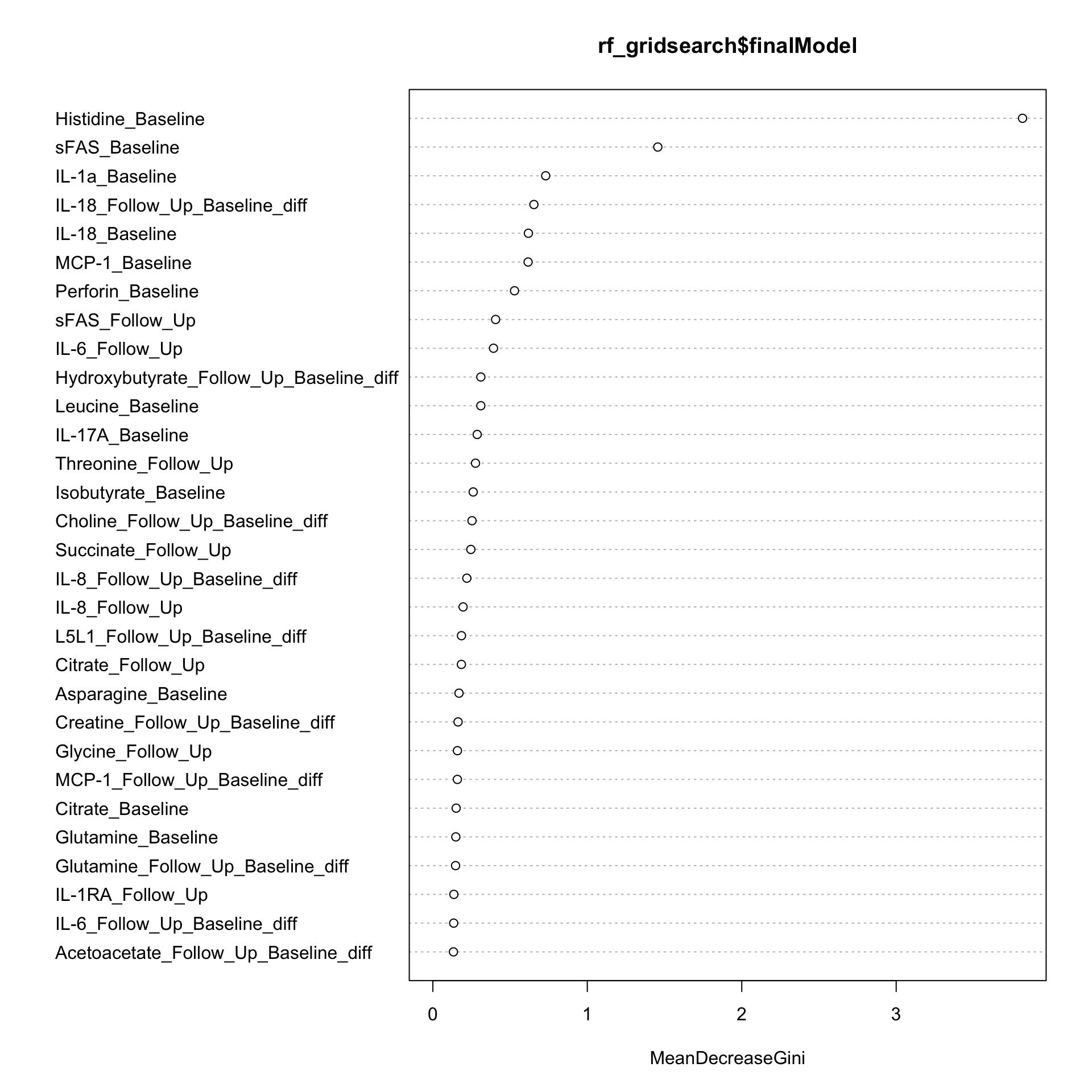
SVM with non-linear kernel
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
# Fit the model
svms <- train(X, y, method = "svmRadial",
trControl = train_control,
preProcess = c("center","scale"),
tuneLength = 10)
# Print the best tuning parameter sigma and C that maximizes model accuracy
svms$bestTune sigma C
3 0.003072148 1plot(svms)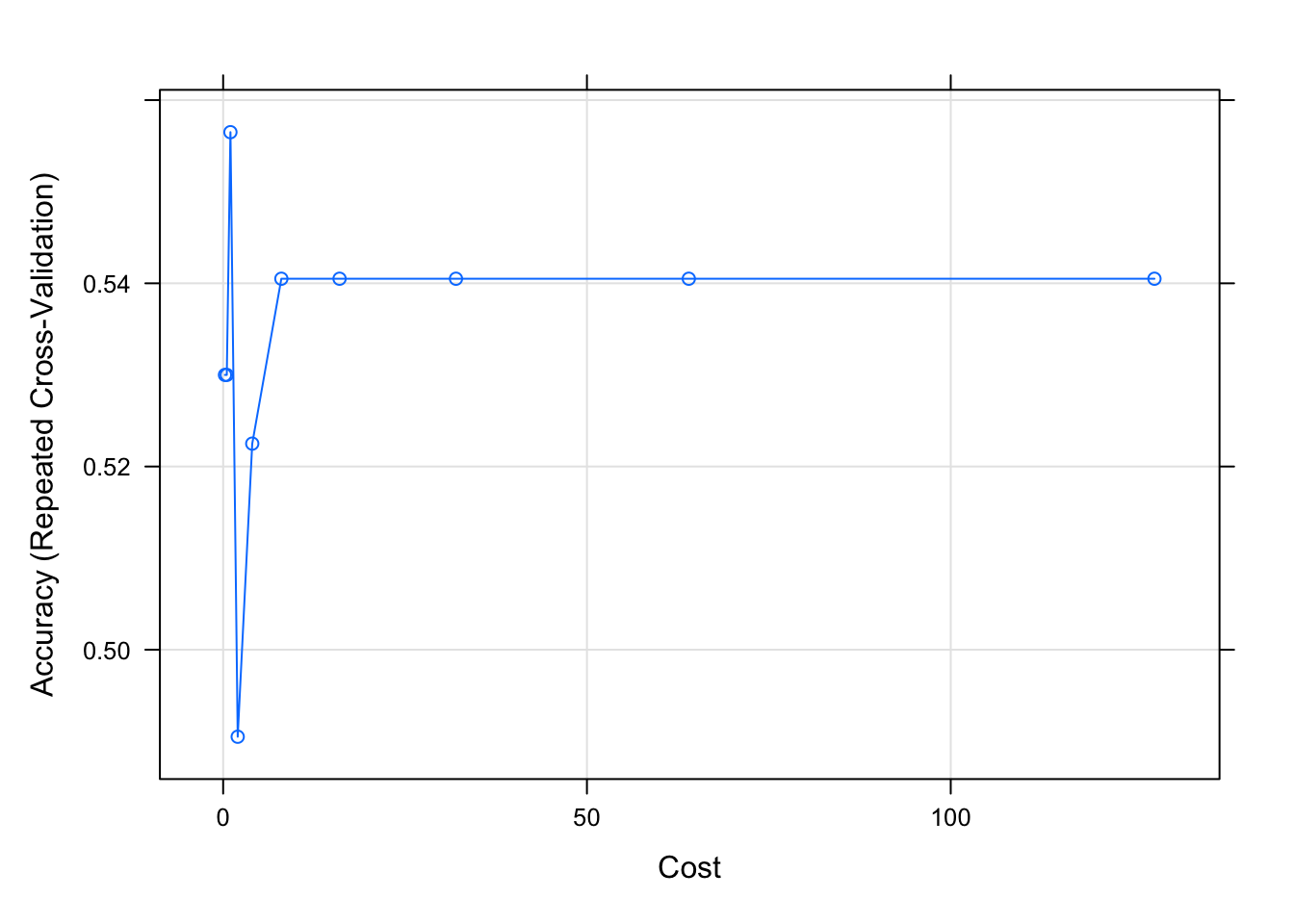
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Multi-nomial regression (Elastic net)
train_control <- trainControl(method="repeatedcv", number=10, repeats=10)
net.fit = train(X, y,
method="glmnet",
trControl=train_control,
metric = "Accuracy",
tuneLength = 10,
preProcess = c("center","scale"),
family="binomial")
plot(net.fit)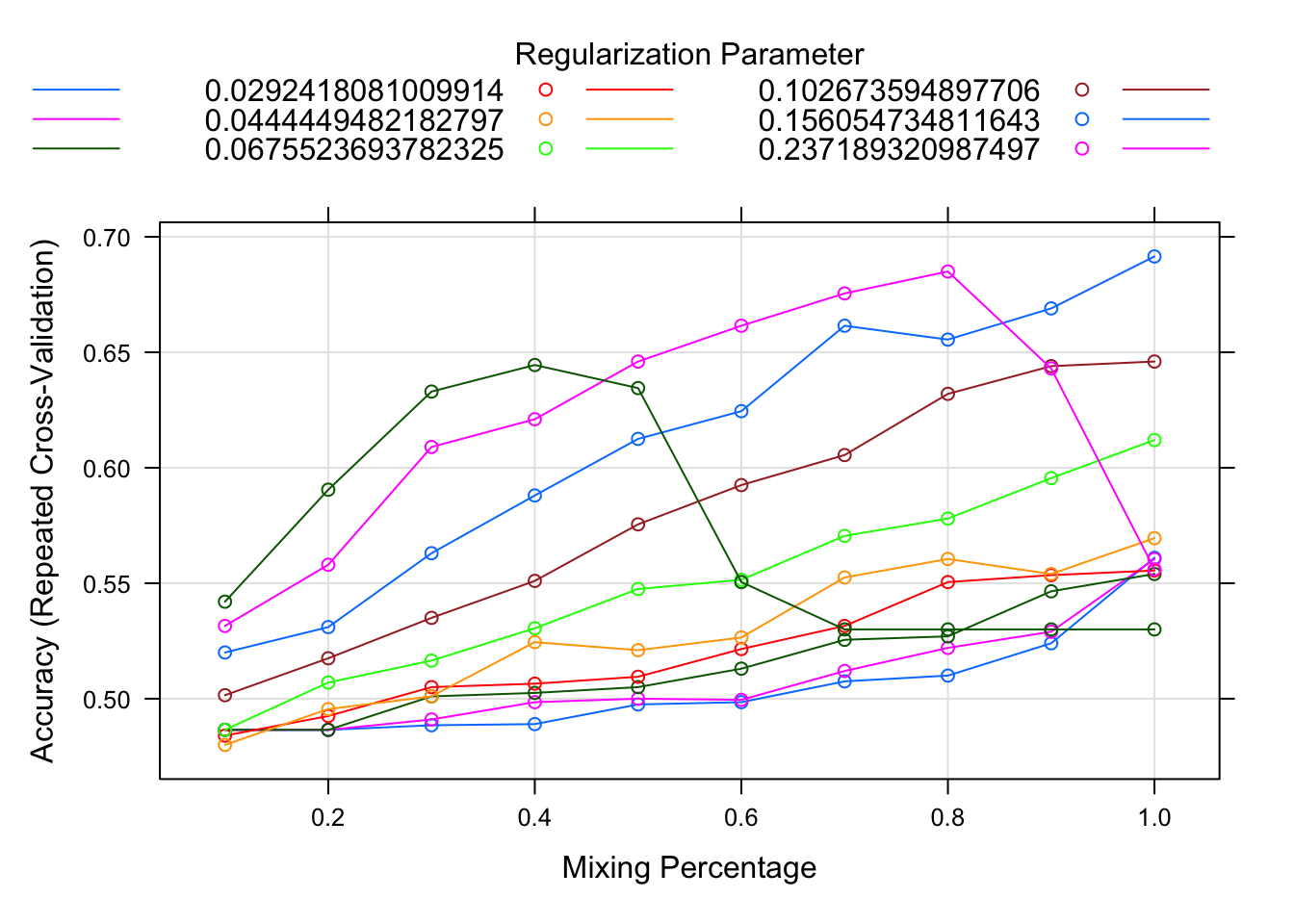
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Feature importance
impTab <- varImp(net.fit$finalModel)
impTab <- impTab[rowSums(impTab)>0,,drop=FALSE] %>%
as_tibble(rownames = "feature") %>%
pivot_longer(-feature, names_to = "group", values_to = "coef") %>%
arrange(desc(abs(coef))) %>%
mutate(feature = factor(feature, levels = unique(feature)))
ggplot(impTab, aes(x=feature, y=coef, fill = group)) +
geom_bar(stat = "identity", position = "dodge", width = .5) +
theme(axis.text.x = element_text(angle = 90, hjust = 1 , vjust=0.5))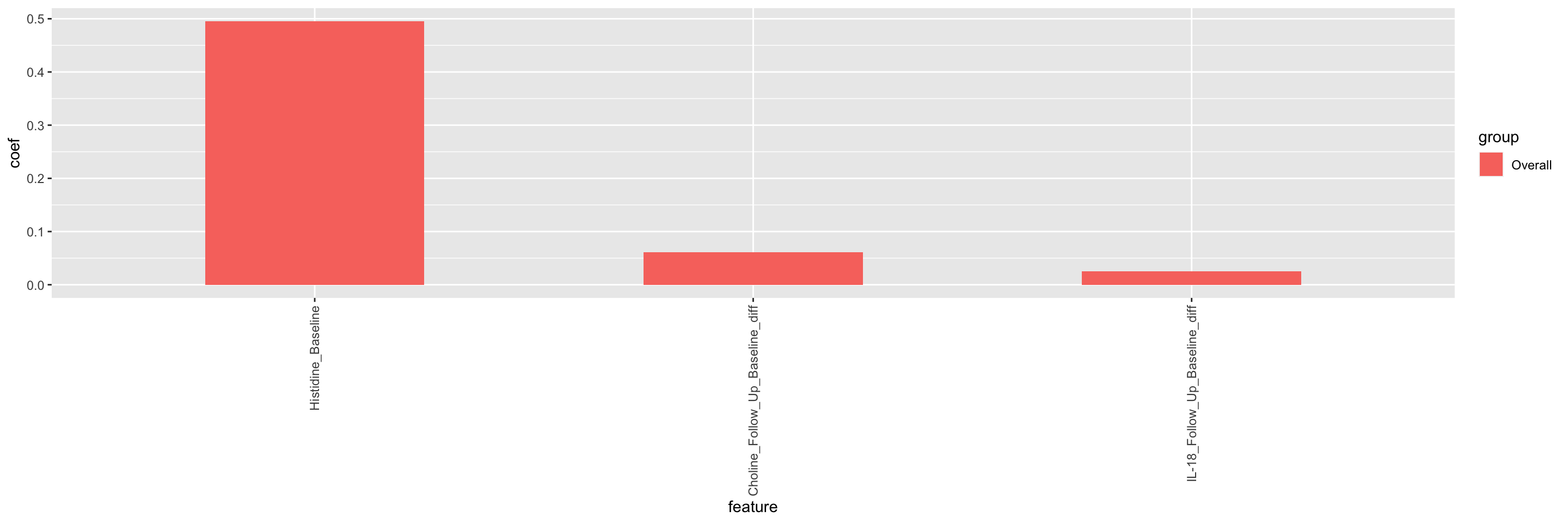
sessionInfo()R version 4.2.0 (2022-04-22)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur/Monterey 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] caret_6.0-93 lattice_0.20-45
[3] randomForest_4.7-1.1 forcats_0.5.1
[5] stringr_1.4.0 dplyr_1.0.9
[7] purrr_0.3.4 readr_2.1.2
[9] tidyr_1.2.0 tibble_3.1.8
[11] ggplot2_3.3.6 tidyverse_1.3.2
[13] jyluMisc_0.1.5 MultiAssayExperiment_1.22.0
[15] SummarizedExperiment_1.26.1 Biobase_2.56.0
[17] GenomicRanges_1.48.0 GenomeInfoDb_1.32.2
[19] IRanges_2.30.0 S4Vectors_0.34.0
[21] BiocGenerics_0.42.0 MatrixGenerics_1.8.1
[23] matrixStats_0.62.0
loaded via a namespace (and not attached):
[1] utf8_1.2.2 shinydashboard_0.7.2 tidyselect_1.1.2
[4] htmlwidgets_1.5.4 grid_4.2.0 BiocParallel_1.30.3
[7] pROC_1.18.0 maxstat_0.7-25 munsell_0.5.0
[10] codetools_0.2-18 DT_0.23 future_1.27.0
[13] withr_2.5.0 colorspace_2.0-3 highr_0.9
[16] knitr_1.39 rstudioapi_0.13 ggsignif_0.6.3
[19] listenv_0.8.0 labeling_0.4.2 git2r_0.30.1
[22] slam_0.1-50 GenomeInfoDbData_1.2.8 KMsurv_0.1-5
[25] farver_2.1.1 rprojroot_2.0.3 parallelly_1.32.1
[28] vctrs_0.4.1 generics_0.1.3 TH.data_1.1-1
[31] ipred_0.9-13 xfun_0.31 sets_1.0-21
[34] R6_2.5.1 bitops_1.0-7 cachem_1.0.6
[37] fgsea_1.22.0 DelayedArray_0.22.0 assertthat_0.2.1
[40] promises_1.2.0.1 scales_1.2.0 multcomp_1.4-19
[43] nnet_7.3-17 googlesheets4_1.0.0 gtable_0.3.0
[46] globals_0.15.1 sandwich_3.0-2 workflowr_1.7.0
[49] timeDate_4021.106 rlang_1.0.4 splines_4.2.0
[52] rstatix_0.7.0 ModelMetrics_1.2.2.2 gargle_1.2.0
[55] broom_1.0.0 yaml_2.3.5 reshape2_1.4.4
[58] abind_1.4-5 modelr_0.1.8 backports_1.4.1
[61] httpuv_1.6.5 tools_4.2.0 lava_1.6.10
[64] relations_0.6-12 ellipsis_0.3.2 gplots_3.1.3
[67] jquerylib_0.1.4 proxy_0.4-27 Rcpp_1.0.9
[70] plyr_1.8.7 visNetwork_2.1.0 zlibbioc_1.42.0
[73] RCurl_1.98-1.7 ggpubr_0.4.0 rpart_4.1.16
[76] cowplot_1.1.1 zoo_1.8-10 haven_2.5.0
[79] cluster_2.1.3 exactRankTests_0.8-35 fs_1.5.2
[82] magrittr_2.0.3 data.table_1.14.2 reprex_2.0.1
[85] survminer_0.4.9 googledrive_2.0.0 mvtnorm_1.1-3
[88] hms_1.1.1 shinyjs_2.1.0 mime_0.12
[91] evaluate_0.15 xtable_1.8-4 readxl_1.4.0
[94] shape_1.4.6 gridExtra_2.3 compiler_4.2.0
[97] KernSmooth_2.23-20 crayon_1.5.1 htmltools_0.5.3
[100] later_1.3.0 tzdb_0.3.0 lubridate_1.8.0
[103] DBI_1.1.3 dbplyr_2.2.1 MASS_7.3-58
[106] Matrix_1.4-1 car_3.1-0 cli_3.3.0
[109] marray_1.74.0 parallel_4.2.0 gower_1.0.0
[112] igraph_1.3.4 pkgconfig_2.0.3 km.ci_0.5-6
[115] piano_2.12.0 recipes_1.0.1 xml2_1.3.3
[118] foreach_1.5.2 bslib_0.4.0 hardhat_1.2.0
[121] XVector_0.36.0 prodlim_2019.11.13 drc_3.0-1
[124] rvest_1.0.2 digest_0.6.29 rmarkdown_2.14
[127] cellranger_1.1.0 fastmatch_1.1-3 survMisc_0.5.6
[130] kernlab_0.9-31 shiny_1.7.2 gtools_3.9.3
[133] lifecycle_1.0.1 nlme_3.1-158 jsonlite_1.8.0
[136] carData_3.0-5 limma_3.52.2 fansi_1.0.3
[139] pillar_1.8.0 fastmap_1.1.0 httr_1.4.3
[142] plotrix_3.8-2 survival_3.4-0 glue_1.6.2
[145] iterators_1.0.14 glmnet_4.1-4 class_7.3-20
[148] stringi_1.7.8 sass_0.4.2 caTools_1.18.2
[151] e1071_1.7-11 future.apply_1.9.0